
Before you even think about writing a single line of training code, your model’s fate is already being sealed. This initial phase of machine learning model training is all about laying a rock-solid foundation, starting with data collection, cleaning, and the often-overlooked art of feature engineering. If you get this part right, you're halfway to a successful model. Get it wrong, and you're just wasting your time.
Building the Foundation for Your Model
The journey to a powerful model begins not with fancy algorithms, but with a simple, sharp question: What problem are we actually trying to solve? Defining a clear business outcome from the get-go dictates everything that follows, from the data you chase down to the metrics you'll eventually use to declare victory.

Let's say you’re tasked with building a customer churn prediction model. The goal is straightforward: spot customers who are about to cancel their subscriptions. This objective immediately gives you a shopping list for data—you’ll need customer demographics, their usage patterns, subscription histories, and any interactions with your support team.
Sourcing and Preparing Your Data
With a clear goal in mind, it's time to roll up your sleeves. Data collection might mean querying internal databases, tapping into public datasets, or even purchasing data from third-party vendors. The quality of this raw material is everything. There’s a reason the global AI training dataset market is exploding, jumping from $1.9 billion in 2022 to a projected $2.7 billion in 2024. This boom underscores just how vital high-quality, relevant data is.
Of course, raw data is almost never model-ready. It’s usually a mess—full of missing values, bizarre inconsistencies, and outliers that can send your model completely off track.
This is where the real work begins. Before feeding data into a model, it needs to be rigorously prepared. The table below breaks down the key stages and highlights why each step is so critical for the training process.
Key Data Preparation Stages and Their Impact
| Stage | Objective | Impact on Model Training |
|---|---|---|
| Data Cleaning | Fix or remove errors, inconsistencies, and missing values. | Prevents the model from learning from incorrect or skewed data, leading to more accurate predictions. |
| Data Transformation | Standardize or normalize data into a suitable format (e.g., scaling numerical features). | Helps algorithms converge faster and perform better, especially for distance-based models like SVMs. |
| Feature Engineering | Create new, more informative features from existing raw data. | Unlocks hidden patterns and provides stronger signals, often boosting model performance more than algorithm tuning. |
| Data Splitting | Divide the dataset into training, validation, and testing sets. | Ensures an unbiased evaluation of the model's ability to generalize to new, unseen data. |
Each of these stages is a non-negotiable part of building a reliable model. Skimping on any of them is a recipe for poor performance down the line.
The old adage "garbage in, garbage out" has never been more true. A model trained on messy, incomplete data will spit out flawed predictions, no matter how sophisticated your algorithm is.
The Creative Power of Feature Engineering
Once your data is clean, you move on to what I consider the most creative part of the process: feature engineering. This is where you transform raw data into features that give your model real insight into the problem.
Think about our churn model again. A raw data point like a "last login date" isn't particularly useful on its own. But if you engineer a new feature from it, like "days since last login," you’ve suddenly created a powerful predictor. You could do the same thing by creating features like "average session length" or "number of support tickets in the last 30 days."
This is all about creating strong signals for your model to learn from. I've seen great feature engineering outperform a more complex algorithm time and time again. These foundational steps are the essence of true data-driven decision-making, ensuring that your insights are built on a solid, well-crafted base.
For teams looking to simplify the deployment side of things, exploring no-code AI backend solutions can be a smart move. These platforms handle much of the underlying infrastructure, letting you stay focused on what really matters: the quality of your data and the business problem you're solving.
Choosing the Right Algorithm for the Job
Alright, your data is clean and ready to go. Now comes one of the most pivotal moments in the entire process: picking your algorithm. This isn't about chasing the latest, most complex model making headlines. It's about being a craftsman and selecting the right tool for the job you need to do. Get this part right, and you'll save yourself a world of headaches down the line.
The first thing to do is clearly define your problem. What are you actually trying to achieve?
Are you predicting a number, like the future price of a house or how much a customer will spend? That's a classic regression problem. Or are you trying to sort things into buckets, like deciding if an email is spam or not? That’s classification. Maybe you need to find natural groupings in your data without any labels, like segmenting your customers by their shopping habits. That’s a job for clustering.

If you're ever feeling lost, this flowchart from Scikit-learn is an absolute lifesaver. It’s a fantastic visual guide that helps you navigate from the characteristics of your problem straight to a handful of solid algorithmic candidates.
Matching Models to Problems
For regression tasks, I almost always start with something simple like Linear Regression. It's fast, incredibly easy to interpret, and gives you a solid performance baseline. If the data's relationships are more tangled and non-linear, it's time to bring out the bigger guns like Decision Trees, or even better, powerful ensemble methods like Random Forests and Gradient Boosting Machines.
The story is similar for classification.
- Logistic Regression is your workhorse for straightforward binary classification problems.
- Support Vector Machines (SVMs) can work wonders when there's a clear separation between your classes.
- Neural Networks, especially deep learning models, are the undisputed champions for complex challenges like image recognition or natural language processing, where they can uncover incredibly subtle patterns.
A rookie mistake I see all the time is reaching for a deep neural network for every single problem. Please don't. Start with the simplest model that can solve the problem effectively. A well-tuned Random Forest will often run circles around a poorly configured neural network, and it’ll train in a tiny fraction of the time.
Of course, the trend toward massive models is impossible to ignore. Since 2017, we've seen an explosion in model size to push performance boundaries. The original GPT transformer had around 120 million parameters. Today, models in Meta's Llama family can have 70 billion parameters—a nearly 600-fold leap that has unlocked some seriously impressive capabilities. If you're curious, you can dive deeper into the state of foundation model training trends to see just how fast things are moving.
The Non-Negotiable Data Split
Before you write a single line of training code, you have to do this. It’s arguably the most critical step in the entire workflow: splitting your data. This simple act is your main line of defense against a model's arch-nemesis, overfitting. Overfitting is what happens when your model memorizes the training data—noise, quirks, and all—but completely fails when it sees new, real-world data.
To avoid that disaster, you'll split your dataset into three separate piles:
- Training Set: This is the lion's share, typically ~70-80% of your data. The model learns all its patterns from this set.
- Validation Set: This smaller chunk (~10-15%) is your model's sparring partner. You use it to tune hyperparameters and check how well the model is learning without tainting its final evaluation.
- Test Set: This final piece (~10-15%) is locked away in a vault. You do not touch it. It’s only used once, at the very end, to get an honest, unbiased report card on how your final model will perform in the wild.
Always Start with a Baseline
Last but not least, set up a baseline model. This is a dead-simple, almost "dumb" model that serves as your reality check. For a classification task, your baseline might be a model that just guesses the most common class every time. For regression, it could be one that always predicts the average value.
Your sophisticated new model must beat this baseline. If it can't, something is seriously wrong with your data, your features, or your overall approach. It’s a simple trick that keeps you grounded and gives you a clear measure of success.
Diving Into the Core Training Process
Alright, you’ve wrestled your data into shape and picked a promising algorithm. Now comes the exciting part—the actual machine learning model training. Think of this less like hitting a "start" button and more like coaching an athlete. It’s an active, hands-on cycle of learning, testing, and refining where your model evolves from a blank slate into a finely-tuned predictive engine.

At its heart, the training loop is beautifully simple. The model takes a guess on a piece of data, we calculate how wrong that guess was, and then we use that error to nudge the model's internal wiring in the right direction. Do this millions of times, and slowly but surely, the model learns the patterns.
The Levers You Can Pull
To guide this learning journey, you have a few critical controls. Getting a feel for these is what separates someone using off-the-shelf models from someone who can truly build a great one.
- Loss Function: This is your scoreboard. It’s a mathematical function that tells you, in no uncertain terms, how badly the model messed up its last prediction. The whole game is about getting this score as low as possible.
- Optimizer: If the loss function is the score, the optimizer is the coach. It takes the error score and decides precisely how to adjust the model’s parameters (its internal "knobs") to do better next time. Gradient Descent is a classic example.
- Learning Rate: This might be the single most important hyperparameter you'll tune. It dictates the size of the adjustments the optimizer makes. Set it too high, and your model will frantically overshoot the best solution. Too low, and training will take forever.
These three elements work in a constant feedback loop, pushing the model closer and closer to accurately mapping your inputs to the correct outputs. Of course, this entire process hinges on having high-quality data to begin with; you can explore more about why data annotation is critical for AI startups.
Finding a Rhythm with Batches and Epochs
Feeding a model the entire dataset at once is usually impractical. Instead, we break it down into smaller, digestible pieces called batches. The model looks at one batch, calculates the error, and makes a quick update.
When the model has seen every single batch in your training set one time, that's called an epoch. A full training run typically consists of many epochs, giving the model multiple chances to see the data and refine its understanding. The batch size itself is a balancing act: small batches can offer quick, dynamic learning but are often noisy, whereas larger batches give a more stable sense of the error but eat up a lot more memory.
The sheer horsepower needed for this process has exploded. The compute used for top-tier AI models has been skyrocketing by 4 to 5 times per year since 2010. This trend underscores just how critical efficient training strategies have become.
Keeping an Eye on Performance
Effective machine learning model training isn't a "set it and forget it" task. You have to be an active observer. By tracking how your model performs on both the training data and your separate validation set, you can get a clear picture of what's happening under the hood.
Plotting these "training curves" is the best way to diagnose common problems. Here's what you’re looking for:
- Underfitting: Both your training and validation errors are stuck at a high level. This is a tell-tale sign your model is too simple for the job and just can't grasp the patterns in your data.
- Overfitting: This is the classic rookie mistake. Your training error drops to nearly zero, but your validation error stays high or even starts climbing. The model has basically memorized the training examples, down to the noise, and can't generalize to new data.
- The "Just Right" Fit: This is the goal. Both training and validation errors smoothly decrease and then level off at a low value. It shows your model learned the general patterns without getting bogged down by the specifics of the training set.
Catching these issues early is key. If you spot underfitting, you might need a more powerful model architecture. If overfitting starts to creep in, you can fight back with techniques like regularization, adding more data, or simply stopping the training process before the model goes too far off the rails. This iterative refinement is the true craft of building an exceptional model.
Tuning Hyperparameters for Peak Performance
Getting a model to train successfully is a huge step, but the job isn't done. The real magic, the thing that separates a decent model from a truly exceptional one, often lies in hyperparameter tuning.
These aren't the parameters your model learns during training; they're the high-level settings you choose before training even starts. Think of them as the knobs and dials on your learning algorithm. For a Random Forest model, this could be the max_depth of each decision tree or n_estimators, which is just the total number of trees you want in the forest. Tweaking these values, even slightly, can have a massive impact on your model's performance.
Picking the Right Tuning Strategy
You can't just guess your way to the best hyperparameter combination—the search space is often enormous. This is where systematic tuning strategies come into play. They provide a structured way to explore the possibilities and zero in on what works best.
Let's walk through a few of the most common approaches I've used in projects over the years.
Comparison of Hyperparameter Tuning Methods
Choosing the right tuning technique is a trade-off between computational cost and potential performance gains. This table breaks down the most common methods to help you decide which is the best fit for your specific machine learning project.
| Method | How It Works | Pros | Cons |
|---|---|---|---|
| Grid Search | Exhaustively tries every single combination of hyperparameters from a predefined grid. | Guarantees finding the best combination within the grid. Simple to understand and implement. | Extremely slow and computationally expensive, especially with many hyperparameters or a large range of values. |
| Random Search | Samples a fixed number of random combinations from the specified hyperparameter distributions. | Much faster than Grid Search. Often finds a "good enough" or even optimal solution much quicker, as not all hyperparameters are equally important. | Doesn't guarantee finding the absolute best combination. Performance can be a bit hit-or-miss depending on the number of iterations. |
| Bayesian Optimization | Builds a probability model of the objective function and uses it to intelligently select the next set of hyperparameters to evaluate. | Highly efficient. It "learns" from past results to focus on the most promising areas of the search space, often finding better results with fewer iterations. | More complex to set up and understand. Can sometimes get stuck in a local optimum. |
Ultimately, the choice depends on your project's constraints. If I'm working with a small search space and have plenty of computing power, Grid Search is a reliable, if brute-force, option. More often than not, Random Search is my go-to for a great balance of speed and results. But when I absolutely need to squeeze every last drop of performance from a model, Bayesian optimization is the clear winner.
This visual really drives the point home, showing how different strategies balance the number of configurations tested against the accuracy they achieve.
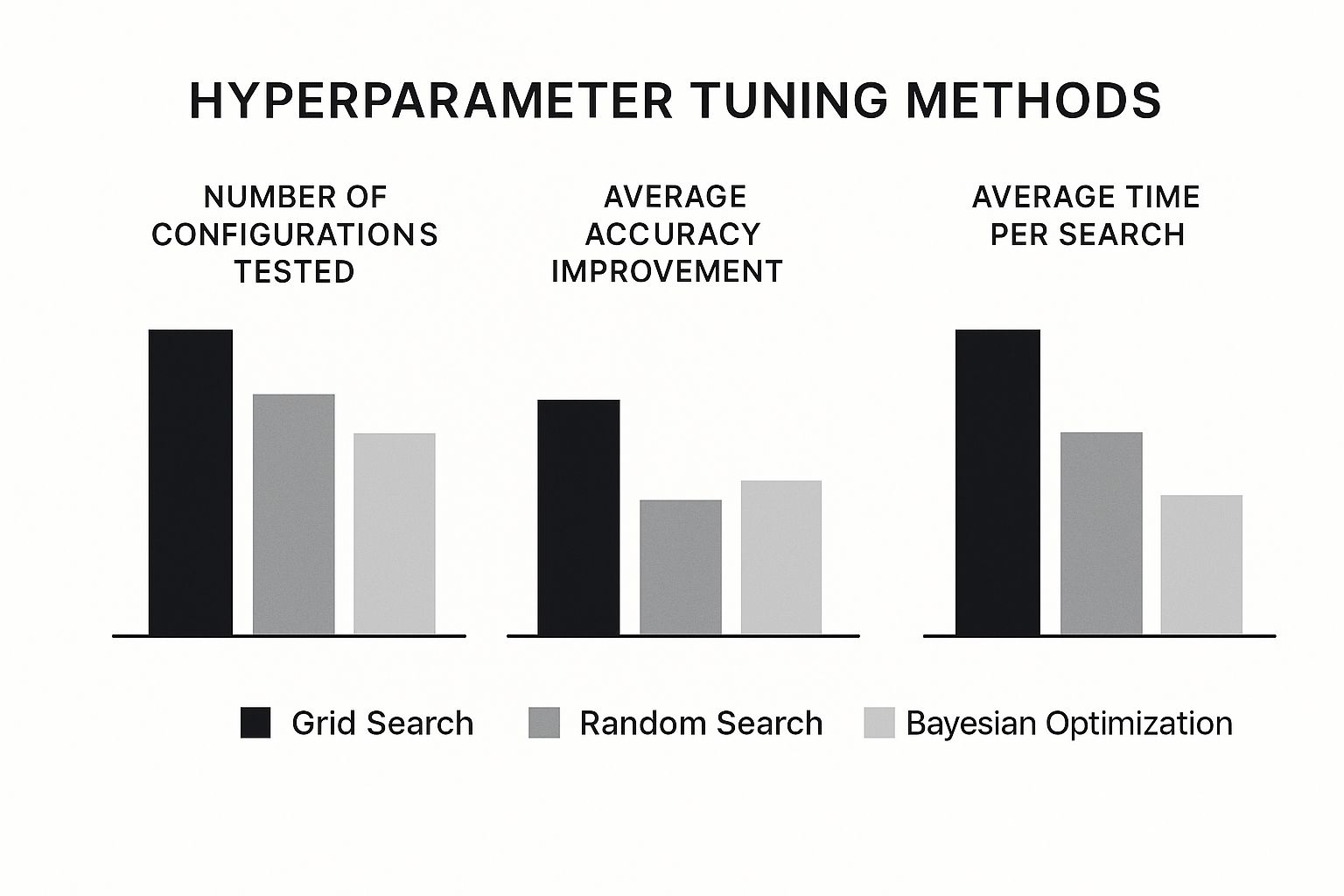
As you can see, a smarter approach like Bayesian Optimization can hit peak performance with far less time and computational effort than an exhaustive grid search.
Don't Forget Cross-Validation
Here’s a classic trap: you tune your hyperparameters and find a combination that works perfectly on your validation set, only to see it fall flat on new, unseen data. This happens when you overfit to your validation data. The solution is k-fold cross-validation.
Instead of a single train/validation split, you divide your training data into ‘k’ equal-sized chunks, or "folds." Then, you run the process ‘k’ times.
- On the first run, you train the model on folds 2 through k and validate it on fold 1.
- On the second run, you train on folds 1 and 3 through k and validate on fold 2.
- …and so on, until every fold has been used as the validation set exactly once.
By averaging the performance across all k folds, you get a much more reliable and stable estimate of how your chosen hyperparameters will perform in the real world. It’s a critical step for building a robust model.
This is non-negotiable: Never, ever touch your final test set during hyperparameter tuning. That data has to stay locked away until the very end. Its only purpose is to give you one final, unbiased score of your finished model.
Figuring Out if Your Model Actually Works
After all the time you've spent prepping data, picking an algorithm, and tweaking hyperparameters, you've finally reached the moment of truth. Let me be clear: training a model is the easy part. The real work is proving it actually does what you need it to do. This is what separates a genuine solution from a cool science experiment that never sees the light of day.
Now’s the time to unlock that pristine, untouched test set you've been saving. This data—which your model has never seen before—is your only real, unbiased look at how it will behave out in the wild. If you skip this or fudge it, you're only fooling yourself.
Why "Accuracy" Is a Trap
It's so tempting to just look at a model's accuracy score and call it a win. A model that's 95% accurate sounds great, doesn't it? Well, maybe not. Accuracy can be a dangerous and misleading metric, especially when you're working with imbalanced datasets.
Think about a fraud detection model where only 1% of all transactions are actually fraudulent. A lazy model could simply predict "not fraud" every single time and achieve 99% accuracy. It would look fantastic on paper, but it would be completely useless because it fails at its one job: catching fraud. This is exactly why we need to dig deeper with a better set of metrics that tell the whole story.
Key Metrics for Classification Models
When you're dealing with classification, you have to understand the types of mistakes your model is making. The best way to visualize this is with a confusion matrix, which neatly breaks down your model's predictions into four buckets: True Positives, False Positives, True Negatives, and False Negatives.
From there, we can calculate much more insightful metrics:
- Precision: When the model says something is positive (like "fraud"), how often is it right? You'll want high precision when the consequences of a false positive are high.
- Recall (Sensitivity): Of all the things that were actually positive, how many did the model manage to find? High recall is non-negotiable when you can't afford to miss something important, like in a medical diagnosis.
- F1-Score: This is a neat little metric that balances precision and recall. It's often my go-to when both false positives and false negatives are equally bad.
Don't just grab a metric off the shelf. Your choice needs to tie directly back to your business goal. For a spam filter, you'd probably lean towards high precision to avoid sending an important email to the junk folder (a false positive). But for a cancer screening model, high recall is the only thing that matters—you have to catch every potential case (a false negative).
Measuring Performance for Regression Models
What if your model is predicting a number, like a house price or next month's sales figures? The rules change. Accuracy is meaningless here. Instead, you need to measure how big your model's errors are.
A few of my favorite tools for this are:
- Mean Absolute Error (MAE): This is just the average of the absolute differences between what the model predicted and the actual value. It’s great because it's easy to explain—an MAE of $5,000 means your price predictions are off by $5,000 on average.
- Root Mean Squared Error (RMSE): This one is similar, but it squares the errors before averaging them and then takes the square root. The effect? RMSE penalizes bigger mistakes much more heavily. It's the right choice when a few huge misses would be disastrous for your project.
Keep in mind that the quality of your initial data annotations directly impacts all of these evaluation metrics. If you're looking for help getting this right, checking out a list of top data annotation service companies can be a good starting point for finding a reliable partner.
And while you’re focused on model-specific metrics, it doesn't hurt to think about the bigger picture. Concepts from general Software Development Key Performance Indicators can offer a broader perspective on measuring success. Ultimately, this final evaluation is the gatekeeper that decides if your model is ready to deliver real value.
Answering Your Toughest Model Training Questions
As you get your hands dirty with model training, you'll inevitably run into the same challenges that have tripped up countless engineers before you. Getting past these hurdles is what separates a proof-of-concept from a production-ready model. Let's tackle some of the most common questions head-on.
What Do I Do About Imbalanced Datasets?
This is a classic problem. You have a dataset where one class is the needle in a haystack—think fraud detection, where 99% of transactions are legitimate. A lazy model can achieve 99% accuracy just by guessing "not fraud" every single time, which is completely useless.
Your job is to force the model to pay attention to that rare, but critical, minority class. There are a couple of solid ways to do this:
- Resampling Techniques: You can either create more of the minority class (oversampling) or reduce the majority class (undersampling). A go-to algorithm for oversampling is SMOTE (Synthetic Minority Over-sampling Technique), which intelligently generates new synthetic data points rather than just duplicating existing ones.
- Adjusting Class Weights: This is often a more elegant solution. You can tell your model's loss function to penalize mistakes on the minority class more heavily. It’s like telling the model, "I care 10x more about you getting this rare case right."
When you're dealing with imbalanced data, throw accuracy out the window. It's a vanity metric here. Instead, you need to live and breathe metrics like F1-score, Precision, and Recall. They’ll give you the real story of how well your model is identifying the class you actually care about.
What’s the Real Difference Between a Parameter and a Hyperparameter?
Getting this straight is crucial. It’s the difference between just running code and truly understanding how to build a model.
Parameters are what the model learns on its own from the data. They are the internal guts of the model—the weights in a neural network or the coefficients in a linear regression. You don't set these; the training process discovers them.
Hyperparameters are the knobs and levers you control before training even starts. Think of them as the high-level strategy for the learning process. Things like the learning rate, the number of trees in a random forest, or the regularization strength are all hyperparameters. Your job is to tune them to create the best possible learning environment for your model.
How Long Should I Actually Train My Model?
There’s no magic number, and the answer is almost always "less time than you think." Your goal isn't to train forever; it's to train just long enough to get the best performance on new, unseen data.
Train for too long, and you fall into the trap of overfitting, where the model essentially memorizes the training data, quirks and all. It becomes brilliant at predicting the data it's already seen but terrible at generalizing to anything new.
The industry-standard technique to avoid this is called early stopping. While training, you continuously evaluate your model’s performance on a separate validation dataset. You're looking for that sweet spot where the validation error stops improving and begins to creep back up.
The moment that validation error bottoms out, you stop. That’s it. You’ve found the point of peak performance before overfitting kicked in, saving yourself a ton of wasted compute time in the process.
When Is It a Good Idea to Use Transfer Learning?
Honestly? Almost anytime you're working on a standard problem (like image or text classification) and don't have a Google-sized dataset. Transfer learning is one of the most practical and powerful tools in our arsenal.
The idea is simple: take a massive model that's already been pre-trained on a huge, general dataset (like ImageNet for images) and then fine-tune it on your own smaller, specific dataset. You're essentially starting with a model that already has a deep understanding of general features—edges, textures, shapes—and just teaching it the specifics of your task.
This approach gives you a massive head start. It means you need far less data, your training will be exponentially faster, and you'll often end up with a much more accurate model than you could ever hope to build from scratch. Don't reinvent the wheel when you can stand on the shoulders of giants.
At Zilo AI, we provide the high-quality data annotation and strategic manpower solutions you need to build, train, and deploy exceptional AI models. Whether you're refining computer vision algorithms or developing the next generation of language understanding, our services ensure your projects are built on a foundation of excellence. Explore our end-to-end AI data solutions.