
At its heart, AI data annotation is the process of labeling raw data—things like images, text files, and audio clips—so that machine learning models can actually understand what they're looking at.
Think of it like teaching a child what a cat is. You don’t just show them a picture; you point to it and say, “That’s a cat.” You do this over and over with different cats. Each time, you're creating a connection between the visual information (the picture) and a label ("cat"). Data annotation does the same thing for AI, turning messy, raw information into the clean, organized fuel it needs to learn.
So, What Is AI Data Annotation, Really?
Fundamentally, data annotation acts as a bridge between human knowledge and machine intelligence. AI models, particularly in a setup called supervised learning, can't make sense of raw data on their own. They need context, and that's precisely what annotation provides by adding meaningful tags or metadata.
Let's take a self-driving car. Its cameras are constantly capturing video of the road, but to the AI, it's all just a jumble of pixels. This is where human annotators step in. They might draw boxes around every pedestrian, trace the lane markings on the road, and tag each traffic light with its color. Every single label is a lesson, teaching the AI what to look for and how to react, ultimately creating a structured dataset it can use to navigate the world safely.
In short, data annotation is the critical translation step that turns the chaotic real world into a structured language machines can comprehend and act on. It’s not just a technical task; it's the very foundation of any successful AI system.
Why Is Everyone Suddenly Talking About Data Annotation?
The demand for high-quality data annotation is exploding, and the reason is simple: the unbelievable growth of unstructured data. We're generating staggering amounts of raw information every day, but most of it is useless to an AI until it’s been properly labeled.
In fact, forecasts show that the amount of unstructured data managed by companies is set to double, thanks in large part to the rise of generative and conversational AI. As a result, an estimated 80% of new data pipelines are now being built specifically to handle, annotate, and store this kind of information. That's a huge shift. If you're curious to see more, you can explore a detailed forecast on data annotation market trends.
This trend points to a clear reality: the more advanced our AI becomes, the more we need meticulously annotated data to train it. The two go hand in hand.
Core Components of Data Annotation
To really get a handle on the concept, it helps to break the process down into its essential parts. While the specifics can change from one project to the next, just about every data annotation effort relies on these key pieces working together.
Here’s a simple breakdown of what’s involved:
| Component | Description | Example |
|---|---|---|
| Raw Data | The initial, unlabeled information you start with. | A folder containing 10,000 images of city streets. |
| Guidelines | A detailed rulebook explaining exactly how to label the data for consistency. | Instructions stating that all cars must be labeled with blue bounding boxes and all pedestrians with red ones. |
| Annotators | The human workforce (or AI-assisted tool) that actually applies the labels. | A team of specialists drawing boxes around cars and people in the images, following the guidelines perfectly. |
| Labeled Data | The final, annotated dataset that’s ready to be fed into a machine learning model. | The 10,000 images, now with every car and pedestrian accurately labeled and ready for training. |
When these components come together effectively, you get a reliable, high-quality training dataset—the bedrock of a powerful and accurate AI model.
Exploring the Core Types of Data Annotation

The world of AI data annotation is incredibly diverse, reflecting the countless forms of data that AI models need to understand. Think of it like a specialized toolkit. You wouldn't use a hammer to turn a screw, and similarly, the way you label an image is fundamentally different from how you'd handle an audio file.
Nailing the right annotation method from the start is a critical first step toward building a high-performing model. Let’s dive into the three main categories—image, text, and audio—and explore the specific techniques that make each one tick. These are the very methods that power many of the AI applications you probably use every day.
Image Annotation: Teaching Machines to See
Image annotation is probably the most intuitive type of data labeling. It’s all about teaching machines to perceive and interpret the visual world, just like we do. This is the bedrock of computer vision, a field that allows models to identify objects, understand what's happening in a scene, and even navigate physical spaces. From autonomous cars to advanced medical imaging, this process is essential.
Here are a few of the most common techniques:
- Bounding Boxes: This is the classic approach. Annotators draw a simple rectangle around an object. It’s a straightforward and effective way to teach an AI the location and general dimensions of things like cars, pedestrians, or products on a store shelf.
- Polygons: When objects have irregular shapes that a simple box can't capture, polygons are the answer. Annotators click a series of points around an object's precise border. This detail is vital in medical AI for tracing a tumor on a scan or in agriculture for identifying a specific type of leaf blight.
- Semantic Segmentation: This is a much more granular technique that classifies every single pixel in an image. Instead of just drawing a box around a car, every pixel that makes up the car gets tagged as "car." This creates an incredibly detailed map of the scene, which is crucial for self-driving vehicles that need to know the exact boundary between the road and the sidewalk.
- Keypoint Annotation: Also known as pose estimation, this method involves marking critical points on an object to understand its structure or posture. A perfect example is tracking human movement by placing keypoints on joints like elbows, knees, and shoulders—a technique heavily used in sports analytics and fitness apps.
Text Annotation: Unlocking the Meaning in Language
Text annotation gives machines the ability to read and comprehend human language. It’s the magic behind the curtain for chatbots, email spam filters, and search engines. By adding contextual labels to text, we teach models to grasp grammar, sentiment, user intent, and the subtle relationships between words.
A foundational task in text annotation is Named Entity Recognition (NER). This is all about identifying and categorizing key pieces of information—think names of people, organizations, locations, and dates. When a customer service chatbot asks for your "order number," it's NER that helps it find and extract that specific string of digits from your reply.
Another powerful technique is sentiment analysis, where text is labeled as positive, negative, or neutral. Brands use this at a massive scale to sift through social media comments and product reviews, giving them a real-time pulse on what customers really think. It’s how unstructured opinions are turned into meaningful business insights.
Audio Annotation: Making Sense of Sound
From the voice assistant on your phone to automated transcription services, audio annotation is the key to unlocking the information held within sound. This process involves converting spoken language into text and, more importantly, adding layers of context that a machine can understand.
The most basic form is audio transcription, which is simply writing down spoken words. This is the foundation for tools like the transcription services offered by Otter.ai or the voice commands understood by Siri and Alexa. But annotation often goes much deeper.
Speaker diarization, for instance, answers the crucial question: "Who spoke, and when?" This technique segments an audio file and assigns each spoken part to a specific person. It’s invaluable for creating accurate transcripts of meetings or multi-person interviews, ensuring that quotes are attributed to the right individual and preserving the flow of the conversation.
To help tie all this together, here’s a quick look at how these data types, techniques, and real-world applications connect.
Comparing Data Annotation Types and Use Cases
| Data Type | Annotation Technique | Primary Use Case |
|---|---|---|
| Image | Bounding Boxes, Polygons, Segmentation | Self-driving cars, medical image analysis, retail object detection |
| Text | NER, Sentiment Analysis, Text Classification | Chatbots, spam filters, brand reputation monitoring, search engines |
| Audio | Transcription, Speaker Diarization | Voice assistants, meeting transcription, call center analytics |
By understanding these distinct categories of AI data annotation, you can see why a one-size-fits-all approach just doesn't work. The choice of technique directly shapes what an AI model can learn and, ultimately, determines how well it will perform in the real world.
Why High-Quality Annotation Is Non-Negotiable

In the AI world, there's an old saying that's more of a fundamental law: Garbage In, Garbage Out (GIGO). It's a simple, blunt truth. No matter how sophisticated your algorithm is, it's only as good as the data it learns from. This is where the real work of artificial intelligence data annotation shines.
Think of your AI model as a brilliant student, and the annotated data is its textbook. If that textbook is riddled with errors, fuzzy definitions, and mixed signals, even the most promising student will struggle. In the same way, an AI trained on inaccurate or inconsistent data will inevitably make poor decisions.
The fallout from bad annotation isn't just theoretical; it has serious real-world consequences. A self-driving car might misread a stop sign because of a poorly drawn bounding box. A medical AI could overlook a tumor because the training data was inconsistently labeled. These aren't just edge cases—they are the direct results of cutting corners on data quality.
The True Cost of Inaccurate Labels
Low-quality data doesn't just hobble performance. It kicks off a domino effect of expensive and time-consuming problems. When a model isn't working right, the knee-jerk reaction is often to blame the algorithm itself. Teams can lose weeks, even months, trying to tune the model, only to realize the problem was in the training data from the very beginning.
This frustrating cycle of retraining and debugging is sometimes called "model debt," and it can completely derail a project's timeline and budget. This is why investing in meticulous, high-quality annotation upfront isn't just an expense—it's the best insurance policy you can buy against failure down the road.
Quality annotation is proactive risk management. It transforms data from a potential liability into a reliable asset, ensuring the final AI system is trustworthy, fair, and genuinely useful.
The industry is waking up to this reality. We're seeing huge growth in the data annotation sector, especially as AI pushes into high-stakes fields like autonomous driving and healthcare. And while automation tools are helpful, they can't replace the nuanced judgment of a human, especially for tasks that demand exceptional accuracy and an understanding of context.
The Pillars of Annotation Quality
Great data isn't about achieving impossible perfection. It's about a relentless focus on three core principles. For new AI companies, getting these right from the start is absolutely crucial. For a deeper dive, check out our guide on why data annotation is critical for AI startups in 2025.
These three pillars form the foundation of any reliable AI model:
- Accuracy: Simply put, the label has to be correct. If a cat is labeled as a dog, you're teaching your model the wrong lesson. It's a fundamental error that poisons the data.
- Consistency: The same rules must be applied everywhere, every time. If one annotator labels "sedan" while another just uses "car," the model gets confused by the mixed signals.
- Completeness: Every relevant object or data point needs a label. A missing label is just as harmful as a wrong one because it teaches the model that it's okay to ignore important things.
A Real-World Failure Story
I once saw a project involving a retail AI designed to track shelf inventory. The initial version was a mess—it was constantly mixing up products that looked similar. The dev team spun their wheels for weeks, convinced they needed a more powerful object recognition model.
But the algorithm wasn't the problem. It was the data. The original annotation guidelines were too vague. Annotators were drawing bounding boxes that accidentally included shadows or bits of the next product over. These tiny, seemingly innocent errors taught the AI to associate products with the wrong visual cues.
Once they went back and re-annotated the entire dataset with clear, strict guidelines, the model's accuracy shot up almost overnight, with no changes to the code. It’s a classic story that serves as a powerful reminder: in artificial intelligence data annotation, the painstaking details are everything. It’s the invisible work that ultimately decides whether an AI project gets off the ground or crashes and burns.
How the Data Annotation Process Actually Works
Turning a massive folder of raw, unlabeled data into a clean, model-ready dataset can feel like a monumental task. But it's not as chaotic as it might seem. The entire artificial intelligence data annotation workflow is a lot like a well-oiled production line, following a clear, logical sequence of steps.
Interestingly, the process doesn't start with the data. It starts with the rules.
Step 1: Defining Project Guidelines
Before a single file is touched, the first and most critical step is to create a detailed set of annotation guidelines. Think of this document as the project's constitution—it's the single source of truth that ensures every person working on the data does so with absolute consistency. In my experience, fuzzy instructions are the number one killer of data quality.
Your guidelines need to provide crystal-clear answers, ideally with visual examples:
- What are we labeling? Be incredibly specific. "Vehicles" isn't good enough. Does that mean cars, trucks, and buses, but not motorcycles or scooters? Define it all.
- How should we label it? Specify the exact tool and technique. Should a car get a simple bounding box, while a pedestrian needs a more precise polygon? What's the required level of detail?
- What about the weird stuff? You have to plan for edge cases. What happens when an object is halfway cut off at the edge of the frame or is blurry? Clear rules for these situations prevent annotators from making inconsistent judgment calls.
Step 2: Sourcing Data and Choosing Tools
With your rulebook in hand, it's time to gather the raw data—your images, text files, or audio clips. This is also when you need to pick your annotation software.
Don't rush this decision. The right tool won't just support your data type; it will make the entire process faster and more accurate. As you evaluate platforms, you also need to decide if you're building an in-house team or bringing in outside experts. For larger or more complex projects, many businesses turn to specialized partners. Browsing a list of the top data annotation service companies can give you a good sense of who has the right expertise.
Step 3: The Annotation and Quality Control Loop
This is where the real work happens. The data gets labeled, and then immediately checked for quality. This isn't a simple hand-off; it’s a constant, repeating cycle of annotation, review, and feedback. The best systems use a multi-layered approach to catch every possible error.
A key concept here is Human-in-the-Loop (HITL). It's the simple but powerful idea of combining the raw speed of AI-assisted tools with the nuanced judgment of human experts. An AI might pre-label 80% of an image, but a person is always there to review, correct, and ultimately approve the final output.
This infographic perfectly shows the simple feedback loop that's at the heart of quality annotation.
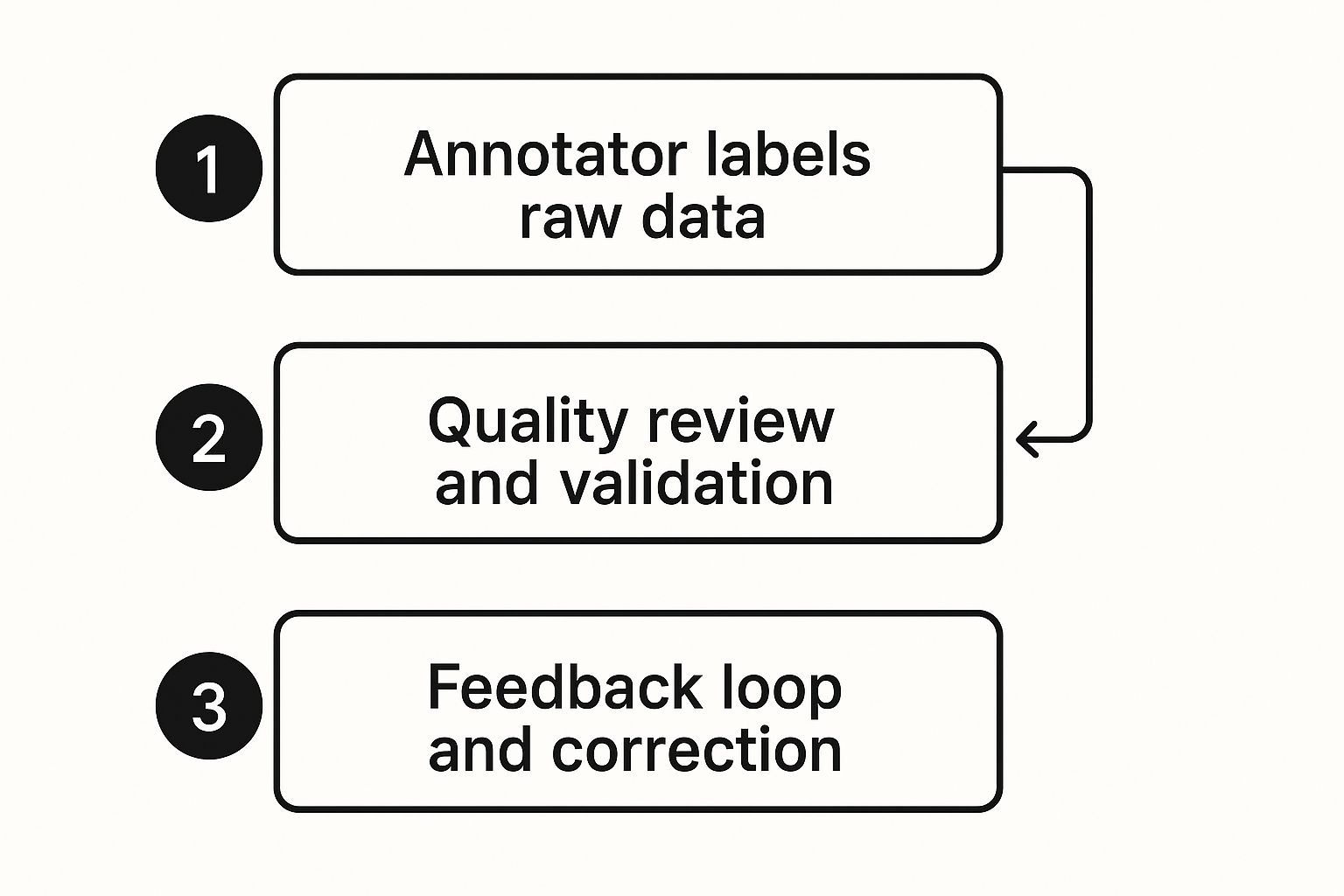
That simple three-part cycle—label, review, and correct—is what separates a truly great dataset from a merely average one.
Let’s dig a bit deeper into this all-important cycle:
- Initial Annotation: The first pass. An annotator, sometimes helped by an AI assistant, applies the initial labels to the raw data, strictly following the guidelines.
- Quality Review: A second person, usually a more senior team member or a dedicated QA specialist, meticulously reviews the work. They're looking for accuracy, consistency, and any deviation from the guidelines. This is also where you might use a consensus model, where several people label the same piece of data to flag any disagreements.
- Feedback and Correction: If the reviewer finds any mistakes, they're sent back to the original annotator with specific, constructive feedback. The annotator makes the fixes, and the data goes back for another round of review.
This loop repeats as many times as necessary until the data hits the project's quality target, which is often an accuracy score of 99% or higher. Only then is the dataset considered "gold standard" and truly ready to train a reliable AI model.
Mastering Quality Control in Data Annotation

Exceptional artificial intelligence data annotation doesn't happen by accident. It's the direct result of a systematic, almost obsessive focus on quality. Think of it like a chef meticulously tasting every component before it goes into the final dish. You have to constantly check your labels to avoid feeding your AI model "poisoned" data before it even starts training.
High-quality data isn't about getting everything perfect on the first pass. That’s a fantasy. It’s really about having solid systems in place to catch and fix the human errors that will inevitably pop up. This deliberate, structured approach is what turns a decent dataset into a great one—the kind of reliable foundation that high-performing AI models are built on.
The Power of Clear Annotation Guidelines
If there's one thing that can make or break an annotation project, it's the guidelines. This rulebook is your first and best defense against inconsistency and confusion. Vague instructions are a recipe for disaster. They force annotators to guess or make their own judgment calls, which is a surefire way to end up with a messy, unreliable dataset.
Your guidelines are essentially the assembly manual for your data. A well-written guide will use plain language and plenty of visual examples to head off questions before they can gum up the works. It needs to spell out not only what to label but, just as crucially, what not to label.
Your annotation guidelines are the ultimate source of truth. A project's success often hinges on how much time was invested in making this document unambiguous, comprehensive, and easy for every annotator to follow.
This manual shouldn't be set in stone, either. Treat it as a living document. As your team encounters tricky edge cases and new scenarios, you’ll need to update it with new rules. This ensures everyone, from the person who started on day one to the one who starts on day 100, is working from the exact same playbook.
Using Consensus to Find the Truth
So, how do you know if a label is actually correct? One of the most effective quality checks out there is consensus scoring. The idea is simple: give the same piece of data to multiple annotators and have them label it independently. If three different people all apply the exact same label, you can be pretty confident it's accurate.
When their labels don't match, it’s a flag. But this disagreement isn't a failure; it's an incredibly valuable data point. It shines a spotlight on parts of your guidelines that might be confusing or on data that is genuinely ambiguous.
For example:
- Minor Disagreement: One annotator draws a bounding box just a little bit wider than another. This might be perfectly acceptable within your project's tolerance.
- Major Disagreement: One annotator calls an object a "truck," while another labels it a "van." This is a critical error. It needs to be escalated to a senior reviewer who can make a final call and, most likely, update the guidelines to clarify the difference between the two.
This method provides a systematic way to find and resolve subjectivity before it corrupts your dataset.
Benchmarking with Gold Standard Datasets
Another powerful tactic is to build what’s known as a gold standard or "honeypot" dataset. This is a small, perfectly labeled collection of your data that has been painstakingly reviewed and certified as 100% correct by your most trusted experts.
This curated set is incredibly useful for a few reasons:
- Training New Annotators: It acts as a perfect set of examples for new team members to learn the ropes.
- Ongoing Quality Checks: You can periodically slip these pre-labeled items into an annotator's regular work queue without them knowing.
- Performance Measurement: How they perform on these "gold" items gives you a crystal-clear, objective metric of their accuracy over time.
By regularly measuring your team against this perfect baseline, you can catch performance dips, identify annotators who might need a bit more coaching, and maintain a consistent quality bar across the board. It’s a straightforward but highly effective way to enforce standards and make sure every label meets your project’s requirements.
The Future of Data Annotation
The world of artificial intelligence data annotation is on the cusp of a major transformation. We're moving away from the days of purely manual labeling and stepping into a more dynamic, intelligent, and collaborative era. While the fundamental goal of teaching machines hasn't changed, how we do it is getting a serious upgrade. These aren't just small tweaks; they're foundational shifts in preparing data for AI.
One of the most impactful trends is AI-assisted annotation. Think of it as a partnership. Instead of a human starting with a blank slate, a preliminary AI model does the first pass—maybe suggesting bounding boxes around objects or segmenting parts of an image. A human expert then comes in to review, tweak, and perfect the AI's work. This "human-in-the-loop" model combines the raw speed of a machine with the nuance and accuracy of a human, dramatically shortening project timelines without sacrificing quality.
We're also seeing a surge in the use of synthetic data. This is exactly what it sounds like: artificially creating computer-generated data to bolster or even stand in for real-world datasets. Imagine trying to teach a self-driving car to navigate a rare blizzard. Instead of waiting for the perfect storm and risking safety, developers can create countless photorealistic, perfectly labeled simulations. This technique is brilliant for filling in data gaps and training models to handle those tricky edge cases safely and effectively.
The Accelerating Market and Ethical Imperatives
The demand for these new methods is staggering. Currently valued at around $2 billion, the AI data annotation service market is set to explode. With a compound annual growth rate of roughly 25%, some analysts predict it could hit an astonishing $10 billion by 2033. This boom is powered by giants in industries like autonomous driving and medical imaging, which need massive quantities of meticulously labeled data to function. You can dive into the full market research on AI data annotation growth to get a sense of just how big this is becoming.
But with great growth comes great responsibility. The future of data annotation isn't just about getting bigger and faster; it’s about building technology the right way. The conversation is shifting heavily toward ethical AI, and that conversation begins with the data.
The core challenge is no longer just about labeling data, but about labeling it fairly. This means actively working to identify and mitigate biases within datasets to prevent AI systems from perpetuating societal inequalities.
This requires a more thoughtful approach to curating datasets to ensure they are diverse and representative. It also means creating annotation guidelines that actively fight against common biases. On top of that, protecting data privacy throughout the annotation process is quickly becoming a baseline requirement. These ethical guardrails are essential for building AI that is not only powerful but also trustworthy and fair for everyone. Ultimately, making sound choices based on this data is paramount. To learn more, check out our guide to master data-driven decision making for your business.
Common Questions About AI Data Annotation
As more teams dive into AI, the same handful of questions about data annotation tend to pop up. Let's clear the air and give you some straight answers based on real-world experience.
Can We Just Fully Automate Data Annotation?
This is the million-dollar question, isn't it? The short answer is no, not if you care about quality. It’s tempting to think we can just let an AI label everything, but that's a surefire way to bake subtle, expensive errors right into your machine learning model.
The sweet spot is a human-in-the-loop (HITL) approach. Think of it as a partnership. The AI does the heavy lifting, maybe suggesting labels or drawing initial boxes, which saves a ton of time. But you absolutely need a human expert to come in, review the work, make corrections, and give the final sign-off. This combination gives you the speed of a machine with the nuance and contextual understanding that only a person can provide.
Data Annotation vs. Data Labeling: What's the Difference?
Honestly, in most conversations, people use these terms interchangeably. They both get at the core idea of adding meaningful tags to raw data so a machine can learn from it.
If you want to get technical, though, there's a slight difference:
Data labeling is often the simpler task. Think of it as slapping a single, high-level tag on something—labeling an entire picture as "cat" or "dog."
Data annotation usually implies something more detailed and complex. It's about drawing precise bounding boxes around cars, outlining a tumor pixel-by-pixel (semantic segmentation), or transcribing speech with exact timestamps.
At the end of the day, both point to the same goal: making raw data machine-readable. Don't get too hung up on the terminology.
How Do You Pick the Right Annotation Tool?
There's no single "best" tool out there. The right platform is the one that fits your project like a glove. Instead of searching for a one-size-fits-all solution, you should evaluate tools based on what you actually need.
Start by asking these questions:
- What kind of data am I working with? Does the tool handle your specific file types, whether it's standard images, complex medical DICOM files, audio, or text?
- What annotation types do I need? Does it have the features for your task, like simple boxes, detailed polygons, keypoints for pose estimation, or relationship annotations?
- How will my team work together? Look for strong collaboration features, like quality control workflows, review queues, and performance tracking.
- Can it handle my project's scale? Will the tool bog down when you upload a million images, or is it built to handle massive datasets efficiently?
How Much Should I Expect to Pay for Data Annotation?
This is a classic "it depends" situation. The cost of an annotation project can swing wildly based on a few key factors.
Complexity is the biggest driver. Drawing a simple bounding box around a car is cheap. Performing pixel-perfect semantic segmentation on a medical scan is not. The required accuracy also plays a huge role—achieving 99% accuracy costs significantly more than hitting 95%.
Other things that move the needle are the sheer volume of data and the expertise required. A project that can be handled by a generalist workforce will be far more affordable than one that requires board-certified radiologists to do the labeling.
At Zilo AI, we know that world-class AI is built on a foundation of world-class data. Whether you need meticulously annotated datasets to train your models or the skilled professionals to get your project off the ground, our end-to-end services are built to help you succeed. Learn how we can fuel your projects at Zilo AI.