
Let's imagine an AI model as a student about to start school. The training data we give it is its entire education—the textbooks, the lessons, the real-world examples. Without that core material, even the most sophisticated AI is just an empty vessel, unable to learn or grow. The quality of this "education" is what ultimately determines how smart and capable the AI becomes.
Why Training Data Is the Bedrock of Your AI

Every impressive AI you see today, whether it's a chatbot answering your questions or a complex algorithm powering a self-driving car, started with data. An AI algorithm is really just a recipe, a set of instructions. But a recipe is useless without ingredients. Training data provides those raw ingredients, giving the algorithm the material it needs to learn, spot patterns, and ultimately make intelligent predictions.
This brings us to a well-known saying in the field: "garbage in, garbage out." It’s a simple but powerful truth. If you feed a model messy, biased, or incomplete information, you can't expect it to produce reliable or fair results. On the flip side, when you start with a high-quality, comprehensive dataset, you empower the model to build a deep and accurate understanding of its subject.
The Pillars of AI Performance
The connection between data quality and model performance is direct and undeniable. Think about how the training data shapes the most critical aspects of any AI system:
- Accuracy and Reliability: An AI trained on a wide variety of correctly labeled examples is far more likely to make accurate predictions when it encounters new information in the real world.
- Fairness and Bias: The data used for training must be a fair representation of reality, free from human biases. If the data is skewed, the AI will be too, which can lead to unfair or discriminatory outcomes.
- Robustness and Generalization: The goal isn't for the AI to just memorize the training examples. It needs to learn the underlying rules and patterns so it can apply that knowledge to situations it has never seen before. Good data makes this possible.
This intense focus on data is what fuels the entire AI industry. In 2025, the global AI market is valued at around $391 billion, and an incredible 83% of organizations consider AI a top business priority. This massive growth isn't just about writing smarter code; it’s about building the infrastructure to collect, clean, and label the vast amounts of data needed to train these systems.
How Data Forges Every Decision
At the end of the day, an AI system is designed to either help humans make better decisions or to automate tasks entirely. The foundation for every single one of those decisions is the data the AI learned from. This principle isn't exclusive to AI; it’s at the heart of modern business strategy. You can see how this works in practice in our guide to https://ziloservices.com/blogs/data-driven-decision-making/.
To help illustrate these fundamental ideas, the table below breaks down the core concepts of training data and why each one is so important for building effective AI.
Core Concepts of AI Training Data
| Concept | Analogy | Why It's Critical |
|---|---|---|
| Data Quality | Cooking with fresh ingredients | High-quality data ensures the AI learns correct patterns, leading to accurate and reliable outputs. |
| Data Quantity | Reading many books on a subject | More data helps the model generalize better and handle a wider variety of real-world scenarios. |
| Data Diversity | Listening to many different perspectives | A diverse dataset prevents bias and ensures the AI performs fairly across different groups and situations. |
| Annotation | A teacher explaining a picture to a student | Proper labeling (annotation) provides the context the AI needs to understand what the data represents. |
This summary really drives home that every aspect of an AI's "upbringing" depends on the information it's given.
An AI model is a direct reflection of the data it consumes. Its knowledge, its blind spots, and its biases are all inherited from the examples it was shown during its education.
To truly appreciate the impact of well-prepared training data, it helps to look at real-world results. Exploring the transformative power of AI in various industries, such as field service, shows how meticulous data enables everything from predicting equipment failures to optimizing a technician's route. Behind every AI success story is a solid data strategy.
Decoding the Different Types of Training Data

Choosing the right kind of data for training your AI model is a bit like an architect picking materials for a new building. You wouldn't build a skyscraper with straw, right? In the same way, the data you feed your AI has to be the right fit for the job you want it to do. An AI developer needs to understand their materials—the fundamental types of data—just as an architect knows the difference between steel and concrete.
At a high level, all AI training data falls into three main categories. Each one has a unique structure, its own set of strengths, and specific problems it's best suited to solve. Getting a handle on these is the first real step toward building a powerful and reliable AI model.
Structured Data: The Organized Bookshelf
Imagine walking into a library where every single book is perfectly cataloged and shelved. You know exactly where to find anything you need based on genre, author, or publication date. That, in a nutshell, is structured data. It’s information that’s been neatly organized into tables with clear rows and columns, making it incredibly easy for a machine to process.
Think of an Excel spreadsheet, a customer database in a CRM, or a company's financial records. Every piece of information has a defined place and a clear relationship to everything else. This clean organization makes it the perfect fuel for models that need to:
- Predict customer churn using purchase history and engagement data.
- Forecast sales by looking at historical figures, seasonal trends, and marketing budgets.
- Approve loans by analyzing an applicant's credit score, income, and existing debt.
Because it's already in such a clean format, structured data is often the easiest to get started with. The model can jump right into finding patterns without first having to figure out what the data even represents.
Unstructured Data: The Chaotic Genius
Now, picture the workshop of a creative genius—paintings leaning against the wall, notebooks crammed with ideas, audio recordings on a desk, and papers scattered everywhere. This is unstructured data. It’s raw information that has no predefined format or organization, and it makes up a staggering 80% of all data within most companies.
This category covers a massive range of information, including:
- Images and Videos: Think of photos from a social media feed or footage from a security camera.
- Text Data: Customer emails, online product reviews, social media posts, and news articles.
- Audio Data: Recordings of customer service calls or voice commands given to a smart home device.
Unstructured data is messy, but it’s packed with rich context and nuance. While it requires more sophisticated techniques to make sense of, it’s the key that unlocks some of the most impressive AI applications out there, from self-driving cars that can "see" the road to chatbots that can understand a user's frustration.
The global market for AI training datasets is booming, a clear sign of just how valuable this raw material has become. In 2022, the market was worth around $1.9 billion, and by 2027, text datasets alone are projected to hit $1.85 billion. You can find more details in these AI training data statistics on Scoop.market.us.
Semi-Structured Data: The Best of Both Worlds
Sitting somewhere between the perfectly ordered bookshelf and the chaotic workshop, we have semi-structured data. It doesn’t conform to the rigid rows and columns of a traditional database, but it does contain tags or other markers that help separate elements and create a basic hierarchy.
Some of the most common examples you'll see are:
- JSON (JavaScript Object Notation): A popular format for web data that uses key-value pairs to organize information.
- XML (eXtensible Markup Language): Often used for documents, it relies on tags to define different elements.
- Email Data: An email has some structure (sender, recipient, subject line) but also contains unstructured content (the body of the message).
This hybrid approach gives you more flexibility than structured data but is far easier to parse than purely unstructured information. It's incredibly handy for applications that need to process complex, nested data, like handling order information from an e-commerce site or analyzing web server logs.
Finding and Sourcing High-Quality AI Data

So, you know what kind of data your AI project needs. The next big question is: where on earth do you get it? Finding high-quality data for training is a critical early step, and honestly, it can make or break your model’s success down the line.
The good news is you have a few different paths you can take. The right one for you will really come down to your specific project goals, budget, and just how unique you need your AI to be. Getting this choice right from the start is absolutely crucial.
Tapping into Open-Source Datasets
For a lot of teams, the journey kicks off with open-source data. These are basically massive, public collections of information, often put together by universities, research groups, or even big tech companies. Think of them as the public library for AI—full of amazing resources you can check out and use right away.
Platforms like Hugging Face, Google Dataset Search, and Kaggle are genuine treasure troves. They host thousands of datasets for almost any task you can think of. The image above, from Hugging Face's repository, gives you a peek at the sheer variety available, from text and images to highly specialized scientific data. Using these platforms can seriously speed up the initial phases of a project.
But there's a catch. Open-source data isn't a magic bullet. You have to comb through the licensing agreements to make sure you can actually use the data for commercial projects. On top of that, these datasets can sometimes have hidden biases or just might not be a perfect fit for the problem you’re trying to solve.
Key Insight: Public datasets are a fantastic starting point for prototypes and general models. But they rarely give you a real competitive edge, since everyone—including your competitors—has access to the very same information.
Generating Your Own Synthetic Data
What do you do when the real-world data you need is incredibly rare, expensive to gather, or locked down by strict privacy rules? This is where synthetic data becomes your best friend. It’s data that’s been artificially created by algorithms to mimic the patterns and properties of real-world information.
For instance, a company building self-driving cars could generate thousands of hours of simulated driving footage. This could include rare and dangerous situations, like a child suddenly chasing a ball into the street—scenarios you can’t safely replicate in real life. This approach has some serious perks:
- Perfect Labels: Because a computer program creates the data, the labels are flawless and automatic. This saves an unbelievable amount of time on manual annotation.
- Privacy-Friendly: It contains zero personally identifiable information, which is a massive win for sensitive fields like healthcare and finance.
- Covering Edge Cases: You can deliberately create those weird, outlier scenarios that are missing from your real-world data, making your final model much more robust.
The main challenge? You have to make sure the synthetic data is realistic enough. If it doesn’t accurately reflect the real world, your model might stumble when it finally goes live.
Collecting Proprietary Data for a Competitive Edge
When you're aiming for truly unique AI capabilities, exploring custom solutions often means rolling up your sleeves and sourcing your own data. It’s definitely the most resource-heavy option, but it offers the biggest payoff in terms of competitive advantage. This proprietary data is collected by you, for you, and it belongs exclusively to your organization.
This could mean anything from logging user interactions on your mobile app to snapping photos with special company-owned cameras or recording audio for a one-of-a-kind voice assistant. It requires a serious investment in people and processes, but the end result is a dataset that nobody else on the planet has.
Building this kind of asset almost always involves a detailed pipeline of collecting, cleaning, and labeling the data. If you’re looking for the right partner to handle this critical work, you might want to check out our list of the top 10 data annotation service companies in India. Ultimately, a well-built proprietary dataset is one of the most valuable things an AI-focused company can own.
The Essential Process of Data Annotation
Raw, unlabeled information is basically just noise to an AI model. To turn that noise into something the AI can actually learn from, you have to go through the critical process of data annotation.
Think of it like creating a detailed answer key for every piece of data you plan to feed your AI. Without these labels, your powerful algorithms have no way to connect the dots and learn from the data for training. It's this careful, manual work of adding context—like tagging a photo or transcribing a recording—that transforms a useless dataset into a powerful teacher for your AI.
Core Techniques in Data Annotation
Data annotation isn’t a one-size-fits-all job. The right method depends entirely on what you want your AI to do. An AI built to identify different cat breeds needs a completely different kind of "textbook" than one designed to analyze customer service calls.
Here are a few of the most common approaches you'll see:
- Classification and Categorization: This is the most straightforward technique. You simply assign a single, predefined label to each piece of data. Is this email "spam" or "not spam"? Is this customer ticket a "billing issue" or a "technical problem"? It's a simple, effective starting point.
- Object Detection and Recognition: This is where things get more visual. Annotators draw bounding boxes around specific objects in an image or a video. This is how you teach a computer vision model not just what an object is, but also where it is. It’s the foundational skill for self-driving cars that need to spot pedestrians and traffic signs.
- Semantic Segmentation: Taking it a step further, this technique assigns a class to every single pixel in an image. Instead of just drawing a box around a car, segmentation would color in every pixel that makes up that car. This incredibly detailed approach is crucial for things like medical imaging analysis and advanced robotics.
These annotation methods build the bridge between raw data and a working AI model. For any startup or business getting into AI, getting this right is non-negotiable. You can dive deeper into why data annotation is critical for AI startups in our detailed guide. This is truly where the value of your data is unlocked.
How Data Is Divided for Training and Testing
Once your data is neatly annotated, you can't just dump it all into your model at once. To build an AI that's actually reliable, you have to split your dataset into three distinct piles, each with its own job.
The standard industry practice for this is pretty well-established.
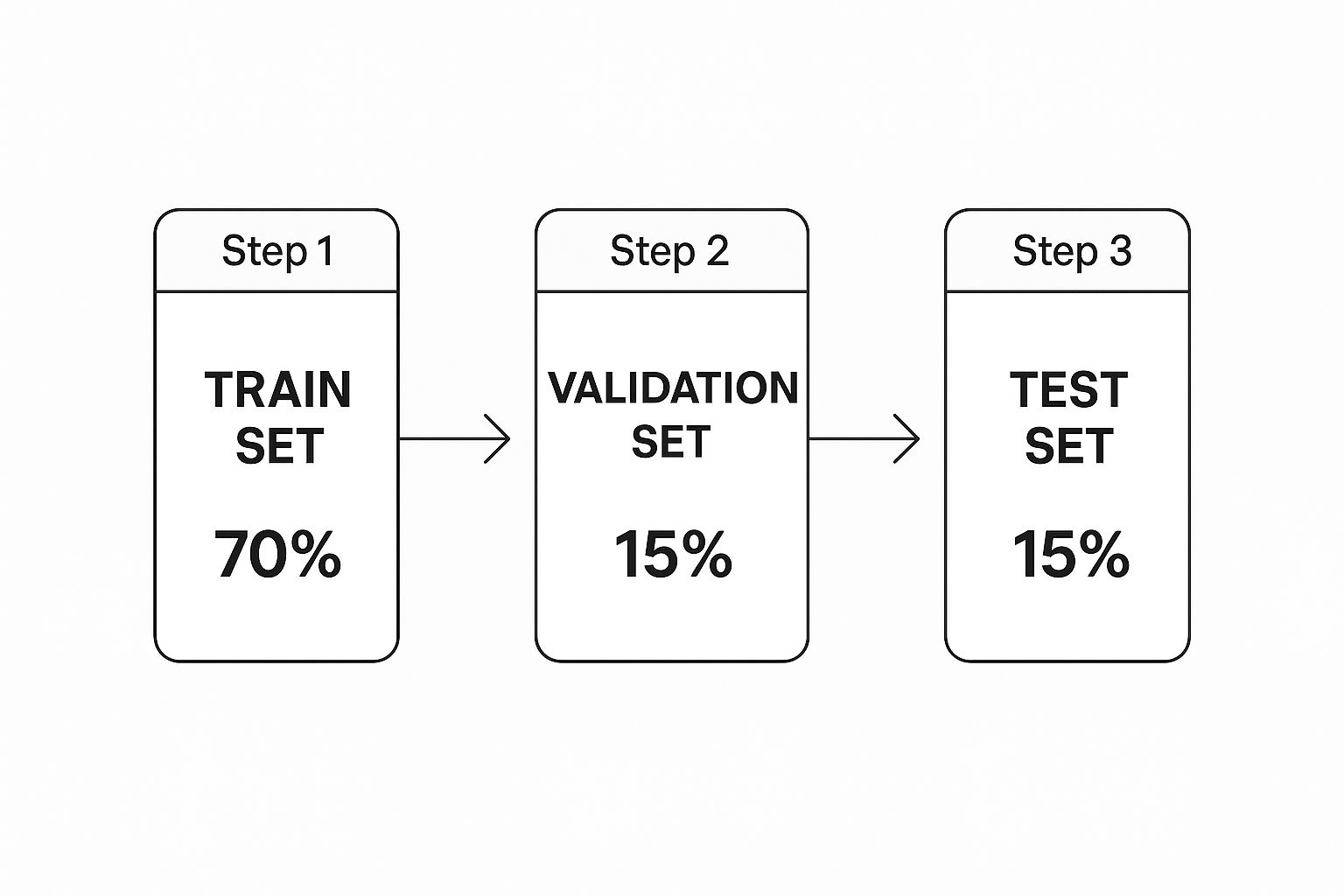
This 70-15-15 split is a simple but powerful way to make sure the model learns properly without just memorizing the answers. It gives you an honest, real-world assessment of how it will perform.
Key Insight: Splitting your data this way is a fundamental quality control measure. The test set acts as a final, unbiased exam, giving you a true picture of how your AI will perform on data it has never encountered before.
Getting the Annotation Done
So, who actually does all this painstaking work? You have a few paths you can take.
Some large companies build their own in-house teams of annotators. This gives them maximum control over quality, but it's often incredibly expensive and slow to get up and running. Another route is using crowdsourcing platforms, but trying to manage quality and consistency across a massive, distributed workforce can quickly become a headache.
For most businesses, the most efficient path is to partner with a specialized service provider like Zilo AI. We give you access to trained professionals and the right tools for the job, ensuring your data for training is prepared accurately and on time. This frees up your team to focus on what they do best—building the actual AI model—instead of getting bogged down in the complex and time-consuming task of data labeling.
Mastering Data Quality to Avoid AI Failure
There's an old saying in computing: "garbage in, garbage out." This has never been more true than in the world of artificial intelligence. It's a simple, almost brutal, truth. If you feed an AI model low-quality data for training, you will get a low-quality model. This isn't just about a dip in performance—it leads to failed projects, wasted resources, and a complete breakdown of user trust.
Getting data quality right isn't a one-time task you check off a list. It's a continuous commitment. It means building a solid framework to ensure your data is accurate, complete, consistent, and truly represents the real world. Without that foundation, even the most sophisticated algorithms are destined to fail.
The Anatomy of Poor Data Quality
Bad data can creep into your pipeline in countless ways, and each one can poison your model from the inside out. The first step to avoiding these issues is knowing what to look for.
Here are some of the most common culprits:
- Inaccurate or Incorrect Labels: This is the classic error. Think of an image of a dog labeled as a "cat." These mistakes teach the model the wrong lessons, which directly leads to flawed predictions.
- Incomplete or Missing Data: When datasets have gaps—like a customer record missing its purchase history—the model can't see the full picture. It misses out on crucial patterns and connections.
- Inconsistent Formatting: A dataset that uses "MM/DD/YYYY" for dates in one column and "Day, Month, Year" in another will confuse an algorithm, causing processing errors and unreliable results.
- Data Drift: The world is constantly changing, and so is data. A model trained on pre-pandemic shopping habits will likely struggle today because the underlying patterns it learned are no longer relevant.
The core principle is crystal clear: an AI model is a direct reflection of the data it learns from. Any flaw, bias, or inconsistency present in the training data will be amplified in the final model's behavior.
Unmasking Bias in Your Training Data
Beyond simple mistakes, one of the most dangerous quality issues is sampling bias. This happens when your training data doesn't fairly represent the real-world population your AI will eventually interact with. For example, a voice recognition model trained mostly on male voices will naturally perform poorly when trying to understand female or higher-pitched voices.
Likewise, a facial recognition system trained on a dataset that underrepresents certain ethnicities will inevitably exhibit biased and even discriminatory behavior. These aren't just technical glitches; they have serious, real-world consequences that erode trust and can cause genuine harm. Actively finding and fixing these imbalances isn't just good practice—it's a non-negotiable part of building responsible AI.
The race to build bigger and more powerful models has only made these challenges harder. The sheer scale and computational power needed for AI have exploded, especially for large language models. In fact, research shows that the compute used for training major AI models has been doubling roughly every five months, with dataset sizes growing every eight months. You can dive deeper into these trends in the 2025 AI Index Report. This rapid growth makes rigorous quality control more critical than ever.
To truly understand the stakes, it's helpful to see a direct comparison of how data quality impacts a project's entire lifecycle.
Impact of Data Quality on AI Model Outcomes
| Metric | High-Quality Data Impact | Low-Quality Data Impact |
|---|---|---|
| Model Accuracy | Consistently high performance and reliable predictions. | Poor accuracy, frequent errors, and unreliable outputs. |
| Project ROI | Faster time-to-market, better user adoption, and higher returns. | Cost overruns, project delays, and potential project failure. |
| User Trust | Builds confidence and encourages long-term engagement. | Erodes user trust, leads to negative brand perception. |
| Fairness & Ethics | Reduces bias, leading to more equitable and fair outcomes. | Amplifies existing biases, causing discriminatory results. |
As the table shows, the initial investment in high-quality data pays off across the board, while cutting corners leads to systemic problems that are difficult and expensive to fix later on.
A Framework for Quality Assurance
So, how do you defend against "garbage in, garbage out"? Your best weapon is a systematic quality assurance (QA) process designed to clean, validate, and maintain your data.
- Define Quality Metrics: First, establish exactly what "good" data means for your specific project. This involves setting clear standards for accuracy, completeness, and consistency.
- Automated Validation Checks: Use scripts to automatically scan for common problems. This can catch things like duplicate entries, formatting errors, or values that fall outside an expected range.
- Human-in-the-Loop Review: Automation is great, but it can't catch everything. You need human experts to review samples of your data, especially the labels, to spot nuanced errors and potential biases that an algorithm would miss.
- Iterative Refinement: Data quality isn't a "set it and forget it" task. You have to continuously monitor both your data and your model's performance, ready to circle back and refine your dataset whenever needed.
This meticulous attention to detail is what separates successful AI projects from the ones that never get off the ground. And remember, just as high-quality training data is essential, so is the quality of the instructions you give the model later on. Learning the best practices for prompt engineering is another key step to getting the most out of your fully-trained models.
So, How Does Zilo AI Fit Into All This?
Knowing the theory behind sourcing, labeling, and cleaning up your data for training is one thing. Actually doing it, efficiently and at scale, is a whole other beast. This is where having the right partner can turn a bottleneck into a superhighway for your AI projects. Think of Zilo AI as your end-to-end data operations team, handling the entire lifecycle so your own people can focus on what they do best: building incredible models.
We close the gap between your AI vision and the high-quality, perfectly prepared data you need to make it a reality. Instead of you having to manage multiple vendors or bog down your internal experts with tedious labeling work, we offer a single, unified solution. Our platform and expert services are built specifically to break through the most common data roadblocks.
From Raw Information to AI-Ready Data, Faster
The path from a messy pile of raw data to a powerful, clean dataset has a few key stages. Each one is a potential minefield for delays and mistakes. Zilo AI’s services are designed to navigate you through them smoothly.
-
Sourcing the Right Data: Need to bulk up your existing datasets? Or maybe you're starting from square one? We help you figure out the best way to get the exact data your model needs to learn effectively.
-
Labeling by Experts: Our team of trained annotators handles everything with precision, from basic image tags to intricate semantic segmentation on video. We work to your exact rules to deliver the accuracy your model needs to perform.
-
Serious Quality Control: We don’t just label data—we obsess over its quality. Our multi-step review process is designed to find and fix any errors, inconsistencies, or hidden biases before they ever have a chance to mess with your model’s performance.
Putting it all together means you get reliable, ready-to-use data in a fraction of the time.
We’ve seen it all. Having successfully annotated over ten million data points at Zilo AI, we know exactly what it takes to produce world-class datasets at scale. That experience means more accurate models and a much quicker path to launch for your AI initiatives.
What a Smoother Pipeline Actually Means for You
Working with Zilo AI isn’t just about handing off a task list; it’s about getting to better business results. When you remove the friction from data preparation, you start to see real, tangible benefits ripple across your organization.
The most obvious win is speed. Getting AI models into production can be held up for weeks, sometimes months, by the slow, manual grind of annotation and QA. By letting our specialists handle it, your highly-skilled engineers and data scientists are freed up to work on core algorithm development and model tuning—the stuff that truly sets you apart.
This newfound efficiency naturally leads to major cost savings. Building an in-house labeling team is a serious commitment of time, money, and management focus. Zilo AI gives you a flexible, on-demand solution that gets rid of the overhead that comes with hiring, training, and managing a separate workforce. You get world-class expertise when you need it, allowing you to put your budget where it matters most.
Ultimately, a faster, more cost-effective data pipeline lets you innovate more quickly, respond to market changes, and build more dependable AI products that your users will trust.
Frequently Asked Questions About Training Data
Let’s wrap up by tackling a few questions we hear all the time on AI projects. Think of this as the practical advice you need to clear up any lingering confusion before you dive in.
How Much Training Data Do I Need for My AI Model?
I wish there were a magic number, but the truth is, it completely depends on your project. The amount of data for training you'll need is tied directly to how complex your task is and the type of AI model you’re building. A simple model trying to classify images as "cat" or "dog" might get by with a few thousand examples, while a massive language model needs to learn from billions.
Here's a better way to think about it: prioritize quality over quantity. Always. It’s far more effective to begin with a smaller set of perfectly labeled data than to feed your model a gigantic, messy dataset full of errors. You can always expand on that solid foundation later with techniques like data augmentation.
The key takeaway is that a well-curated dataset, even if it’s smaller, will almost always teach your model more effectively than a huge, messy collection of information.
What Is the Difference Between Training, Validation, and Test Data?
This is a crucial concept. Imagine you have a big pile of data. To build a reliable model, you need to split that pile into three smaller, distinct sets, each with a specific job.
- Training Data: This is the bulk of your data—usually around 70-80%. It’s the textbook your model studies to learn the patterns and rules for the task at hand.
- Validation Data: This is a smaller portion, maybe 10-15%. You use this set to fine-tune the model during the training process. It acts like a pop quiz, helping you see if the model is genuinely learning or just memorizing the answers.
- Test Data: This final 10-15% is the ultimate final exam. It's kept completely separate and is only used once the model is fully trained. This gives you an honest, unbiased grade on how well your model will perform on brand-new data it has never seen before.
Can I Use Synthetic Data for Training My Model?
Absolutely, and it's an incredibly powerful strategy. Synthetic data is information that's been artificially generated by an algorithm rather than collected from the real world. It’s a lifesaver in situations where real data is scarce, expensive to get, or has strict privacy rules, like in healthcare.
Using synthetic data lets you create perfectly labeled datasets at a huge scale. Even better, it allows you to generate specific examples of rare edge cases that your real-world data might not cover. This helps you build a much more robust and dependable model that won't get thrown off by unusual situations.
Ready to put all this theory into practice? The team at Zilo AI specializes in delivering the high-quality, accurately labeled data your AI initiatives depend on. We manage the entire data pipeline—from sourcing and annotation to quality control—so you can focus on building what’s next. Let us help you accelerate your AI development today.