
In today's fast-paced digital and corporate landscapes, the term 'redundancy' surfaces in two critical, yet distinct, contexts: robust IT architecture and sensitive human resources management. Whether you're safeguarding against a catastrophic server failure or navigating the complexities of workforce restructuring, the core challenge remains the same. The goal is to build resilience and fairness into your systems and processes. Asking the right questions about redundancy is the first step toward creating effective strategies that prevent costly downtime, legal entanglements, and reputational damage.
This comprehensive guide unpacks the most pressing inquiries, offering actionable insights for both technology leaders designing resilient infrastructure and HR professionals managing organizational change. We will move beyond theory to explore the strategic trade-offs, practical implementation details, and essential validation techniques required. By addressing these critical points, you can develop systems and organizational structures that not only survive disruptions but are positioned to thrive through them. Let's examine the essential questions that form the bedrock of a truly resilient enterprise.
1. What's the Right Balance Between Redundancy Level and Cost?
Determining the ideal balance between redundancy and cost is a foundational challenge. The goal is to move beyond a vague desire for "high availability" and adopt a quantifiable, risk-based approach. This strategic decision weighs the potential cost of downtime against the definite cost of implementing and maintaining spare capacity or duplicate components.
From Vague Goals to Quantifiable Metrics
The first step is to translate business needs into technical requirements. Instead of aiming for "100% uptime," calculate the actual financial impact of downtime per hour for a specific system. This figure, known as the Cost of Downtime (CoD), becomes your primary justification for any redundancy investment.
For example, an e-commerce platform might lose $50,000 in revenue for every hour its payment gateway is offline. In contrast, an internal reporting tool might have a CoD closer to $1,000 per hour. This simple calculation immediately clarifies where to allocate your budget. The higher the CoD, the more you can justify spending on robust failover systems.
Key Insight: Don't treat all systems equally. A tiered approach, where you classify applications based on their business criticality and associated CoD, is the most effective way to allocate redundancy resources without overspending.
Actionable Implementation Steps
To find your organization's sweet spot, follow these steps:
- Calculate Business Impact: For each critical service, determine the CoD. Factor in lost revenue, productivity loss, SLA penalties, and potential brand damage.
- Define RTO/RPO: Establish your Recovery Time Objective (RTO) – how quickly you need to recover – and Recovery Point Objective (RPO) – how much data you can afford to lose. An RTO of seconds requires more expensive, automated failover than an RTO of several hours.
- Model Redundancy Options: Compare the total cost of ownership (TCO) for different redundancy levels (e.g., N+1, 2N) against the CoD they mitigate. An N+1 setup might cost $100k but prevent a potential $500k loss, making it a clear win.
This methodical process is one of the most important questions about redundancy to answer, as it turns an abstract concept into a clear, data-driven business decision.
2. How Do We Systematically Eliminate Single Points of Failure?
Addressing Single Points of Failure (SPOFs) is a critical step beyond basic redundancy planning. A SPOF is any component, service, or dependency whose failure will cause an entire system to go offline. Simply adding spare servers isn't enough; true resilience comes from methodically identifying and mitigating these hidden vulnerabilities that can undermine even the most robust architectures.
From Vague Goals to Quantifiable Metrics
The process begins with a comprehensive dependency mapping exercise. Instead of assuming you know your system’s weak points, you must trace every process and data flow to uncover all interconnected components. This includes hardware like load balancers and network switches, software services like databases or authentication systems, and even external API dependencies. The goal is to create a complete architectural blueprint that highlights every potential SPOF.
For instance, a financial trading platform might have redundant application servers but rely on a single, non-redundant matching engine. The failure of that one engine would halt all trading activity, making it a critical SPOF. Similarly, a cloud-native application might function perfectly but depend on a single DNS provider, whose outage could make the entire service unreachable. Identifying these dependencies is the first step toward effective mitigation.
Key Insight: SPOFs often hide in plain sight within shared resources or third-party services. Actively map and document every system interdependency to reveal vulnerabilities that a component-level analysis might miss.
Actionable Implementation Steps
To systematically hunt down and eliminate SPOFs, follow these steps:
- Conduct Dependency Audits: Create and maintain a live diagram of your service architecture. For each component, ask: "What happens if this fails?" If the answer is a total service disruption, you've found a SPOF.
- Implement Architectural Patterns: Use proven designs to build in resilience. For example, Amazon S3 automatically replicates objects across multiple Availability Zones to eliminate single-point storage failures. Likewise, use quorum-based clustering for databases to prevent "split-brain" scenarios where redundant nodes can't agree on the data's state.
- Schedule Regular Failover Testing: Don't wait for a real disaster. Regularly and intentionally "break" components in a controlled test environment to verify that failover mechanisms work as expected. This proactive testing is one of the most vital questions about redundancy to ask, as it validates your theoretical resilience against real-world conditions.
3. Choosing Between Active–Active and Active–Passive Modes
One of the most critical architectural decisions involves choosing how redundant components behave. The choice between an active–active and active–passive configuration directly impacts performance, cost, complexity, and how quickly your system recovers from a failure. This decision determines whether your backup resources are sitting idle or contributing to the live workload.
From Simple Standby to Shared Workloads
The core difference lies in resource utilization. In an active–passive setup, a primary server handles all traffic while a secondary server remains on standby, only taking over if the primary fails. It’s simple and reliable. In contrast, an active–active configuration has all components sharing the load simultaneously. This maximizes resource use but introduces significant complexity in data synchronization and load balancing.
For example, a clustered firewall pair often runs in active–passive mode, where a virtual IP address fails over to the standby unit upon hardware failure. Conversely, a modern database with multi-master replication is active–active, allowing writes to occur on multiple nodes at once for higher throughput and lower latency. The right choice depends entirely on your specific RTO and application requirements.
Key Insight: The decision isn't just about failover; it's a fundamental trade-off. Active–passive prioritizes simplicity and consistency, while active–active prioritizes performance and resource efficiency at the cost of complexity.
Actionable Implementation Steps
To select the appropriate mode for your system, consider the following:
- Analyze Application Needs: Does your application require instant, stateful failover with no interruption? If so, active–active might be necessary. If a few seconds of downtime for a failover event is acceptable, the simplicity of active–passive is often preferable.
- Evaluate Consistency Requirements: Active–active systems must constantly synchronize data between nodes. This can introduce latency and potential for data conflicts. For systems demanding strict transactional consistency, an active–passive model is often safer and easier to manage.
- Monitor Inter-Node Health: Regardless of mode, robust health checks are non-negotiable. For active–active, monitor inter-node latency to prevent "split-brain" scenarios. For active–passive, ensure the standby node is truly ready to take over instantly.
This infographic provides a simple decision tree to help guide your choice based on key priorities.
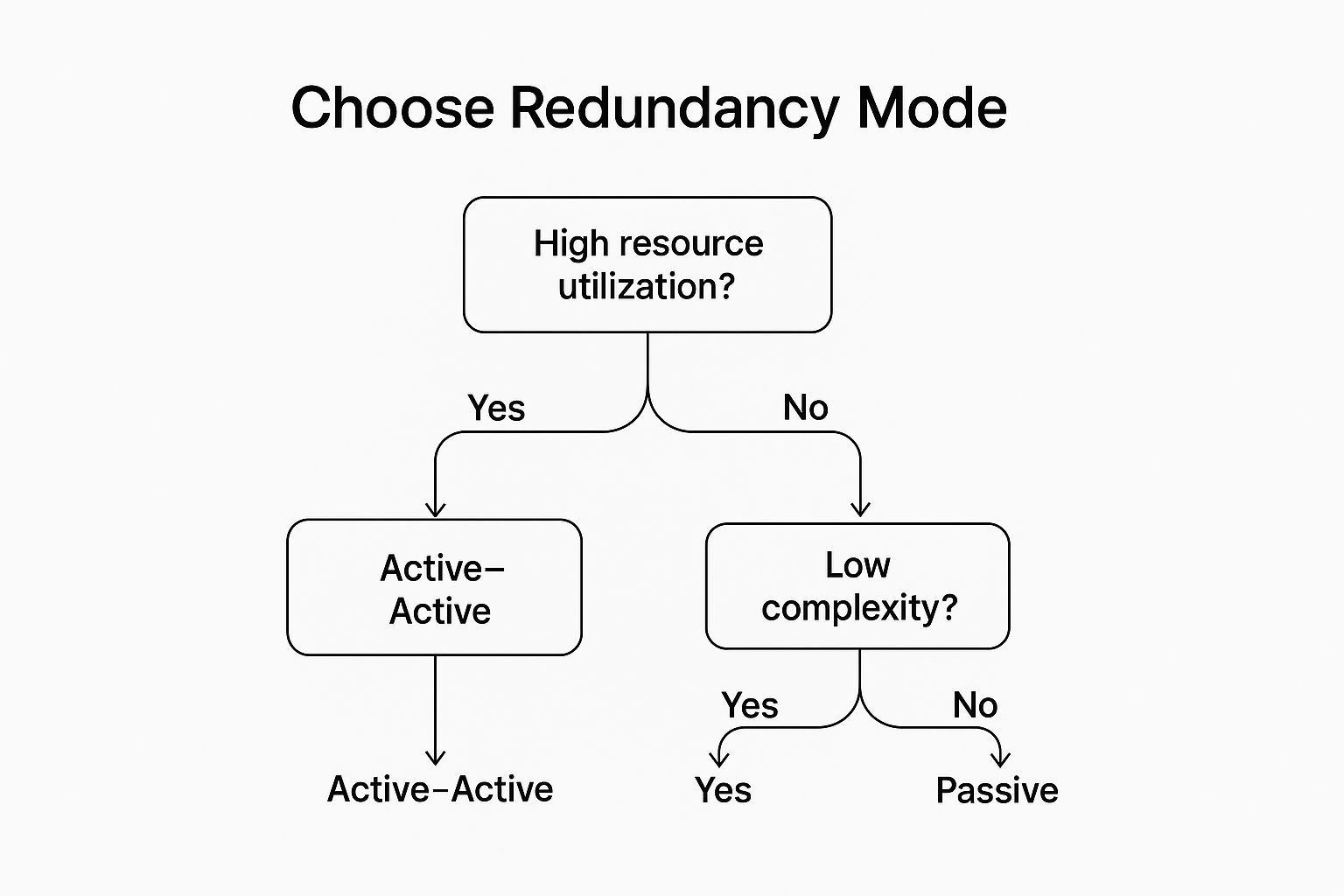
The flowchart highlights how prioritizing either high resource utilization or low complexity points you toward a different redundancy model. Answering these fundamental questions about redundancy helps align your technical architecture with your business goals, ensuring you build a system that is not only resilient but also efficient and manageable.
4. How Do We Test and Validate Redundancy Mechanisms?
Implementing redundant systems without regularly testing them is like owning a fire extinguisher you've never checked; you're operating on faith, not certainty. The goal is to establish a rigorous regimen for simulating failures to verify that failover systems activate as designed. Without proactive validation, latent configuration errors or software bugs can remain undetected until a real crisis strikes, rendering your investment useless.
From Theoretical Safety to Proven Resilience
The first step is to shift the organizational mindset from "hoping it works" to "proving it works." This means treating redundancy testing not as an inconvenience but as a core operational requirement. This approach uncovers hidden dependencies, validates automated triggers, and ensures that recovery procedures are both accurate and familiar to the teams executing them.
For example, many financial institutions perform mandatory quarterly site-switchover drills, shifting live traffic from their primary data center to their disaster recovery (DR) site. Similarly, Netflix famously pioneered "GameDay" exercises, where engineers intentionally cause failures in production environments to validate system resilience. This proactive chaos engineering ensures their platform can withstand unexpected component outages without impacting the user experience.
Key Insight: Redundancy is not a "set it and forget it" feature. It is a dynamic capability that requires continuous validation to remain effective as your systems, software, and configurations evolve over time.
Actionable Implementation Steps
To build a reliable validation process, follow these steps:
- Start Small and Isolate: Begin testing in lower environments like development or staging. Simulate specific failures, such as a single database node or web server going offline, to validate isolated failover mechanisms before moving to more complex scenarios.
- Maintain Clear Runbooks: Document the exact step-by-step procedures for every manual and automated failover scenario. These runbooks should be living documents, updated after every test to reflect lessons learned and system changes.
- Automate Rollback Procedures: Design tests with a clear and automated way to revert to the original state. This minimizes the "blast radius" of a test that goes wrong, particularly in production, and encourages more frequent testing by reducing the associated risk.
Answering these questions about redundancy through consistent testing is the only way to transform a theoretical safety net into a proven, reliable system that you can count on during an actual failure.
5. Performance Impact Versus Redundancy Overhead
A common assumption is that adding redundancy always improves a system, but this overlooks a critical trade-off: performance overhead. Implementing redundant components can introduce latency, consume additional CPU and network resources, and create synchronization bottlenecks. The challenge is to engineer a system where the gains in availability do not come at the cost of an unacceptable performance degradation for the end user.
From Vague Goals to Quantifiable Metrics
The first step is to stop viewing redundancy in isolation and start measuring its performance cost. Instead of just adding a failover database, you must benchmark how replication impacts transaction throughput and query latency. This involves establishing performance baselines for your application before introducing redundant components, creating a clear point of comparison.
For example, a database system might see a significant write penalty when moving from a single instance to a RAID 6 array or synchronous replication. While this configuration protects against multiple drive failures, the added parity calculations could slow down write-intensive operations to a point where it violates service level agreements (SLAs). Similarly, geo-replicated storage provides excellent disaster recovery but can introduce hundreds of milliseconds of latency, making it unsuitable for real-time applications.
Key Insight: Redundancy is not free; it's paid for with resources and performance. Proactively measure this "performance tax" to ensure your availability solution doesn't inadvertently degrade the user experience it's meant to protect.
Actionable Implementation Steps
To balance performance with resilience, follow these steps:
- Benchmark Rigorously: Before and after implementing a redundancy solution, conduct load testing that mimics real-world traffic. Measure key metrics like response time, throughput, and CPU utilization to quantify the exact performance overhead.
- Tune Replication Parameters: Don't accept default settings. Adjust replication configurations like switching from synchronous to asynchronous modes, increasing batch sizes for data transfers, or enabling compression to reduce network load.
- Isolate Redundancy Traffic: Allocate dedicated network interfaces, VLANs, or even physical networks for replication and heartbeat traffic. This prevents contention with primary application traffic, ensuring that failover processes don't slow down normal operations.
Answering these performance-related questions about redundancy is crucial for building systems that are both resilient and responsive, meeting user expectations for speed and uptime simultaneously.
6. Data Redundancy Versus Hardware Redundancy
A common point of confusion is mistaking data redundancy for hardware redundancy. While both are critical for resilience, they protect against entirely different failure scenarios. This distinction is vital because implementing one without the other leaves a significant gap in your continuity strategy, addressing only half of a potential disaster.
From Vague Goals to Quantifiable Metrics
The first step is to recognize what each type of redundancy protects. Hardware redundancy, like having N+1 servers or dual power supplies, protects against the physical failure of a component. If a server fails, a hot-standby takes over. Data redundancy, such as backups or database replication, protects against data corruption, accidental deletion, or ransomware attacks. A perfectly functioning server is useless if the data it holds is gone or encrypted.
For example, a mirrored SAN array (hardware redundancy) ensures service continues if a disk fails. However, if a user accidentally deletes a critical database table, that deletion is immediately mirrored to the redundant disk, wiping out both copies. Conversely, nightly backups to cloud object storage (data redundancy) can restore that deleted table, but they won't help if the primary server's motherboard fails at noon.
Key Insight: Don't treat hardware and data redundancy as an "either/or" choice. A layered approach is necessary. True resilience comes from ensuring you can survive both a component failure and a data integrity failure.
Actionable Implementation Steps
To effectively layer both types of redundancy, follow these steps:
- Map Failure Scenarios: For each critical application, list potential failures (e.g., power outage, disk failure, ransomware, human error) and map which type of redundancy mitigates it.
- Layer Your Defenses: Combine immediate hardware failover with robust data protection. Use hot-standby servers for critical applications (hardware) and implement regular, immutable backups with cross-region replication (data).
- Test Both Restore Paths: Don't just test if your hardware failover works. Regularly conduct data restore drills from your backups to a separate environment to ensure data is viable and your team knows the recovery process.
Answering this is one of the most important questions about redundancy because it forces a holistic view of risk, preventing a false sense of security built on one-dimensional protection.
7. Designing Redundancy in Cloud and Virtualized Environments
Designing redundancy in the cloud shifts the focus from owning physical hardware to strategically leveraging provider services and virtualization. The goal is to build highly resilient systems by distributing components across a provider's vast infrastructure, effectively outsourcing the management of physical servers, networks, and data centers. This approach allows organizations to achieve enterprise-grade durability without massive capital expenditure.
From Vague Goals to Quantifiable Metrics
The core principle is to design for failure by treating provider infrastructure, like Availability Zones (AZs), as independent failure domains. Instead of simply running a virtual machine, you architect your application to survive the failure of an entire data center. This requires understanding the specific service-level agreements (SLAs) and failover capabilities offered by cloud vendors like AWS, Google Cloud, or Azure.
For example, an application using Amazon RDS can be configured for a Multi-AZ deployment. This automatically provisions and maintains a synchronous standby replica in a different AZ. If the primary database fails, AWS handles the failover automatically, typically with downtime measured in just one to two minutes. This turns a potentially catastrophic failure into a minor, self-healing event.
Key Insight: Cloud redundancy isn't about just lifting and shifting your on-premise model. It's about embracing the platform's native tools for distribution, replication, and automated recovery to build systems that are inherently more resilient than their traditional counterparts.
Actionable Implementation Steps
To effectively design for redundancy in the cloud, follow these steps:
- Leverage Managed Services: Use managed services with built-in redundancy, like AWS RDS Multi-AZ or Google Cloud Spanner. These services handle the complex tasks of replication, health monitoring, and failover, reducing your operational burden.
- Automate with Infrastructure as Code (IaC): Use tools like Terraform or AWS CloudFormation to define your infrastructure. This ensures you can consistently and quickly redeploy your entire environment in another region if a large-scale, regional outage occurs.
- Design Across Failure Domains: Distribute your application components across multiple Availability Zones to protect against data center failures. For mission-critical systems, consider a multi-region architecture to protect against regional disasters, while planning for potential data latency and eventual consistency.
Answering these questions about redundancy within a cloud context is crucial for building modern, scalable, and fault-tolerant applications that meet today’s high-availability expectations.
8. Integrating Redundancy into Disaster Recovery and Business Continuity
Redundancy is a tactical component, but its true value is realized when it’s woven into a strategic, enterprise-wide framework. This involves coordinating redundant systems as part of a broader Disaster Recovery (DR) plan and Business Continuity Plan (BCP), ensuring the organization can withstand not just component failures but site-level outages or catastrophic events. This moves the focus from hardware uptime to holistic operational resilience.
From Siloed Systems to Coordinated Response
True business continuity goes beyond having a spare server. It requires a documented plan that connects redundant technology with the people and processes that depend on it. This integration ensures that when a primary site fails, the failover to a redundant system is seamless, and employees know exactly how to resume their duties using the secondary resources.
For instance, a global bank might maintain mirrored data centers with automated failover capabilities. When a disaster strikes one location, the BCP dictates not just the technical switch but also how trading teams, customer support, and compliance officers will operate from their designated recovery sites, connecting to the now-active redundant systems. This coordination prevents technological success from becoming an operational failure.
Key Insight: Redundancy without a corresponding business continuity plan is just expensive spare hardware. The plan gives your redundant infrastructure purpose by defining the human and procedural responses needed to make it effective during a real crisis.
Actionable Implementation Steps
To fully integrate redundancy into your DR and BCP, follow these steps:
- Map Dependencies: Before designing a DR solution, map critical business processes to their underlying IT dependencies. This identifies which systems require the most robust redundancy and informs the sequence of recovery.
- Conduct Cross-Functional Drills: Schedule comprehensive DR drills at least annually. These exercises must involve not just IT staff but also the business units that would be affected, testing both the technical failover and the human response protocols.
- Review and Update Regularly: A BCP is a living document. It must be reviewed and updated after any major organizational or technological change, such as a merger, a new product launch, or a cloud migration.
Answering these questions about redundancy within your BCP framework ensures that your investments protect the entire business, not just isolated pieces of technology.
8-Aspect Redundancy Comparison Guide
| Item | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Balancing Redundancy Level vs. Cost | Medium to High – modular & scalable | Moderate to High – depends on redundancy tier | Improved uptime and fault tolerance | Data centers, telecom networks | Predictable budgeting and capacity forecasting |
| Eliminating Single Points of Failure (SPOF) | High – requires dependency mapping | High – redundant hardware/software | Significant downtime reduction | Critical infrastructures, high-availability platforms | Greater SLA confidence and simpler root-cause analysis |
| Choosing Between Active–Active and Active–Passive Modes | High – complex sync and failover | Moderate to High – depends on mode | Better resource utilization or simpler failover | Databases, clustered firewalls | Active–Active: seamless scaling; Active–Passive: simpler config |
| Testing and Validating Redundancy Mechanisms | Medium to High – automated tests | Moderate – test environment overhead | Early gap detection and incident readiness | Enterprises requiring high operational confidence | Quantifiable RTO/RPO metrics and staff readiness |
| Performance Impact Versus Redundancy Overhead | Medium – tuning and monitoring | Moderate to High – network and CPU usage | Improved resiliency under load | Systems sensitive to latency and throughput | Predictable failover performance and resource utilization |
| Data Redundancy Versus Hardware Redundancy | Medium – depends on chosen approach | Variable – storage vs hardware intensive | Near-zero downtime or data versioning | Backup strategies vs high-availability applications | Cost-effective data protection or transparent uptime |
| Designing Redundancy in Cloud and Virtualized Environments | Medium – infrastructure as code | Low to Moderate – pay-as-you-go model | Elastic scalability and global distribution | Cloud-native applications and global services | Automated health checks and minimized physical overhead |
| Integrating Redundancy into DR and Business Continuity | High – multi-stakeholder coordination | High – standby sites and orchestration | Minimized financial/reputational risks | Enterprises with regulatory/compliance needs | Holistic IT-business process alignment and compliance |
From Questions to Confidence: Building a Resilient Future
Asking the right questions about redundancy is the first, most critical step toward transforming vulnerability into strength. Throughout this guide, we have moved beyond surface-level checklists and delved into the strategic inquiries that separate fragile systems from resilient, anti-fragile ones. We've navigated the complex landscape of redundancy, addressing the pivotal balance between cost and resilience, the subtle but significant differences between active-active and active-passive architectures, and the non-negotiable importance of rigorous, continuous testing. The journey from uncertainty to preparedness begins with a willingness to challenge assumptions and scrutinize every potential point of failure.
The core takeaway is that true resilience is not a static achievement but a dynamic capability. It’s built through a continuous cycle of inquiry, implementation, validation, and iteration. Whether you are safeguarding IT infrastructure or managing human resources with foresight, the fundamental principles remain consistent: anticipate potential disruptions, create robust plans, validate those plans under realistic conditions, and integrate them into your organization's operational DNA. This proactive stance moves you from a reactive, crisis-management mode to a strategic, forward-thinking posture.
Your Actionable Roadmap to Enhanced Resilience
To translate these insights into tangible outcomes, here are your immediate next steps. Treat this as a strategic checklist to guide your efforts in building a more robust and dependable organization.
- Conduct a Comprehensive Redundancy Audit: Begin by using the questions from this article as a framework. Systematically review your critical systems, processes, and teams. Identify every Single Point of Failure (SPOF) and document the potential impact of its loss. This audit forms the foundation of your resilience strategy.
- Prioritize Based on Impact and Likelihood: You cannot address every vulnerability at once. Create a risk matrix that plots the business impact of a failure against its likelihood. Focus your initial resources on mitigating high-impact, high-likelihood risks first, such as securing critical data or ensuring failover for customer-facing applications.
- Schedule Your First "Game Day" Simulation: Move from theory to practice. Plan and execute a controlled test of your redundancy mechanisms within the next quarter. This could be an IT failover drill or an HR cross-training exercise. The goal is to uncover hidden weaknesses in a safe environment before a real crisis strikes.
- Integrate Redundancy into Your Planning DNA: Embed these questions about redundancy into your project kickoff meetings, architectural reviews, and quarterly business planning. Make resilience a mandatory consideration, not an afterthought. This ensures that as your organization scales, its robustness scales with it.
By consistently asking and answering these critical questions, you are not just preventing disasters; you are building a competitive advantage. An organization that can withstand shocks, adapt to change, and maintain continuity of service is one that earns the trust of its customers, retains its top talent, and ultimately, thrives in a world defined by uncertainty. This journey from asking questions to building confidence is the hallmark of a future-ready enterprise.
Navigating the complexities of data redundancy for AI and ML models requires precision and expertise. If your team is grappling with data annotation, transcription, or translation challenges, Zilo AI offers highly reliable, scalable, and secure data services to ensure your projects never face a single point of failure. Fortify your data pipeline by visiting Zilo AI to learn how our human-in-the-loop solutions provide the quality and resilience your AI initiatives demand.