
Image segmentation is all about teaching a computer to see the world not just as a collection of objects, but as a mosaic of precisely defined shapes. It’s the process of partitioning an image into multiple segments, assigning a specific label to every single pixel.
Think of it as transforming a simple photograph into a detailed, understandable map where every element is clearly outlined.
Understanding Image Segmentation in Simple Terms

Let's use a simple analogy to explain what image segmentation really is. Imagine you have a photo and a bunch of digital highlighters. Instead of just drawing a box around a car—which is what we call object detection—you meticulously color in every single pixel that belongs to that car.
That, in a nutshell, is what image segmentation does. It’s a computer vision technique that goes deeper than just identifying objects; it aims to understand their exact shape, boundaries, and location down to the individual pixel.
This pixel-level understanding is the key difference. While object detection answers "what" is in an image and "where" it is roughly, segmentation answers "exactly which pixels" belong to each object.
To put these core ideas into a simple format, here's a quick cheat sheet.
Image Segmentation Core Concepts at a Glance
| Concept | Simple Explanation |
|---|---|
| What it is | A computer vision process that groups pixels in an image into segments. |
| The Goal | To understand the precise shape and boundaries of every object in an image. |
| How it Works | Assigns a label (like "car," "tree," "sky") to every single pixel. |
| Why it Matters | It gives AI a much deeper, more detailed understanding of a visual scene. |
This table shows just how fundamental segmentation is—it’s about moving from a basic "what" to a very specific "where."
From Pixels to Meaningful Objects
This process turns a flat image into a rich source of information, telling an AI system exactly where a pedestrian ends and the sidewalk begins. This kind of deep understanding is the engine behind many of the advanced AI systems we rely on today, from self-driving cars navigating complex streets to medical AI identifying anomalies in scans.
By assigning each pixel to a category, the machine develops a powerful contextual awareness. It doesn't just see a "person"; it sees the exact outline of that person, separating them from the background with incredible accuracy.
To pull this off, algorithms look at an image based on pixel characteristics, generally using two main approaches:
- Similarity: This technique groups pixels together that share common traits. For instance, all pixels within a certain color range or with a similar texture get clustered together to form a segment, like identifying a patch of grass.
- Discontinuity: This method is all about finding the edges. It looks for abrupt changes between pixels to identify boundaries where one object stops and another starts, much like drawing an outline around a shape.
This ability to carefully partition an image is far more than a technical exercise. It’s a crucial step that allows machines to interpret the visual world with a level of detail that starts to resemble human sight, making some truly amazing applications possible.
The Journey from Pixels to Intelligent Vision

A machine's ability to understand an image pixel-by-pixel didn't just appear overnight. It's a journey that started with early computer vision pioneers teaching machines to do something we find simple: just see lines and edges. This first, crucial step was all about detecting abrupt shifts in a pixel’s brightness or color.
From there, the field slowly moved toward grouping those pixels into larger, more meaningful regions. Researchers developed algorithms that could cluster pixels sharing common traits, like similar textures or shades. For decades, though, this was a slow, manual grind that required a ton of human oversight and constant tweaking to get right.
The Rise of Automated Vision
The real breakthrough came with the arrival of machine learning—and more specifically, deep learning. This was a fundamental change in how we tackled computer vision. Convolutional Neural Networks (CNNs) completely rewrote the rules.
Before deep learning, engineers had to painstakingly design "feature extractors" by hand. These were complex sets of rules meant to tell the computer what to look for, like the curve of a fender or the texture of a leaf. CNNs automated that entire process. Instead of being told what features matter, the networks could learn the important patterns on their own, straight from the data. This leap turned image segmentation from a fragile, hand-tuned craft into a robust, automated science that could tackle incredibly complex scenes with stunning accuracy.
This transition from manual feature engineering to automated learning is the single biggest reason modern AI vision is so powerful. It let models find subtle patterns that a human programmer would never even think to look for.
Every step forward was built on the one before it, leading to the powerful vision systems we rely on today. The initial focus on simple edge detection in the 1960s laid the groundwork. By the 1980s, techniques had progressed to region-based methods that grouped pixels into coherent areas. The 1990s introduced clustering algorithms like k-means. But the true revolution kicked off in the 2000s with machine learning, and by 2012, deep learning and CNNs had made segmentation a critical tool in everything from medical imaging to self-driving cars.
The Unseen Engine: Data Annotation
Even the most sophisticated algorithm is useless without good data. This is where the essential process of data annotation comes into play. For an AI to learn how to segment an image, it needs to be trained on thousands of examples where a human has already labeled every single pixel correctly.
This annotated dataset becomes the "ground truth" that the model learns from. It’s an incredibly detailed, time-consuming job that demands absolute precision. Without high-quality, pixel-perfect annotations, even the most advanced CNN will stumble and produce unreliable results.
You can learn more about why data annotation is critical for AI startups in our detailed guide. The quality of this foundational data is what directly dictates the performance and trustworthiness of the final AI model.
Exploring the Three Main Types of Segmentation
Now that we have a handle on what image segmentation is, it's time to dig a little deeper. You see, not all segmentation tasks are created equal. Different goals demand different levels of detail, and the field has evolved to meet those needs. Broadly, we can break it down into three main types, each designed to answer a slightly different question about what's inside an image.
Think of it as climbing a ladder of understanding. The first rung is about classifying everything in broad strokes. The next is about counting and separating individual items. And the top rung? That’s where you get a powerful, all-in-one view. Picking the right approach is the first crucial step in building a computer vision system that actually works.
Semantic Segmentation: Painting by Numbers
The most common and foundational type is semantic segmentation. Let's go back to basics with a coloring book analogy. Imagine a picture of a busy street. If I told you to color every car blue, every tree green, and the road gray, you wouldn't sweat the details of whether there are two cars or ten. You'd just grab your blue crayon and color in anything that looks like a car.
That’s exactly how semantic segmentation operates. Its one job is to assign a class label—like "car," "tree," or "road"—to every single pixel in the image. What you get is a complete, color-coded map of the scene. The catch? It doesn’t distinguish between individual objects. All the cars blend into a single "car" blob, and every person merges into one "person" region.
This method is perfect for jobs where the general category is all that matters.
- Autonomous Driving: A self-driving car needs to know, above all else, which pixels are "road" and which are "sidewalk." It doesn't need to count the individual paving stones.
- Medical Imaging: In an MRI scan, a model can highlight all "tumor" tissue, lumping the cancerous cells into one identifiable area for a radiologist to analyze.
- Satellite Imagery: Environmental scientists use this to classify pixels as "forest," "water," or "urban area" to track deforestation or urbanization over time.
Instance Segmentation: Giving Each Object a Unique Identity
Semantic segmentation is great for that big-picture view, but what if you do need to count the cars in that street scene? This is where instance segmentation shines. It takes things a big step further by not only labeling each pixel with its class but also identifying which specific object it belongs to.
Back to our coloring book. This time, the instruction is to color the first car blue, the second car purple, and the third one red. You’re still identifying all the "car" pixels, but now you’re carefully separating them into distinct objects. It answers the critical question: "How many objects of this class are there, and where are their exact boundaries?"
This ability to tell one object from another is non-negotiable for any task that involves counting, tracking, or interacting with individual items. It provides a much more granular, object-aware understanding of the world.
Instance segmentation is the go-to for more complex challenges:
- Object Tracking: Think of the self-checkout systems at the grocery store. They need to track each unique item a customer scans.
- Robotics: A warehouse robot grabbing items off a shelf has to know the difference between "Box A" and "Box B" to fulfill an order correctly.
- Crowd Counting: To get an accurate headcount in a packed stadium, you have to be able to draw a line around each individual person.
This chart really drives home how much segmentation accuracy has improved, especially with the jump to deep learning.

It’s clear that while older methods like thresholding gave us a starting point, modern deep learning algorithms are what make complex, reliable instance segmentation a reality today.
Panoptic Segmentation: The Best of Both Worlds
Finally, we arrive at panoptic segmentation, the most complete and sophisticated approach of the three. It beautifully marries the strengths of both semantic and instance segmentation to create a single, cohesive understanding of an entire image.
Here's how it works: for every single pixel, a panoptic model does two things at once. First, it assigns a class label (like "car" or "sky"). Then, if that pixel belongs to a distinct object, it also assigns it a unique instance ID.
The key insight is its ability to handle both "things" and "stuff." "Things" are countable objects like cars, people, or dogs—they get both a class label and an instance ID. "Stuff" refers to amorphous background categories like the sky, the road, or a wall. Since you can't count them, they just get a class label.
This unified model provides a rich, holistic view that's more powerful than its parts. It's quickly becoming the gold standard for advanced robotics and autonomous systems that need a full picture to navigate and interact with our complex, messy world.
To make these distinctions crystal clear, here’s a quick breakdown of how these three core types stack up against each other. Each serves a unique purpose, and seeing them side-by-side helps clarify when to use which.
Comparing the Core Types of Image Segmentation
| Segmentation Type | Primary Goal | Example Use Case |
|---|---|---|
| Semantic | Assign a class label to every pixel. | Mapping all road surfaces for an autonomous vehicle. |
| Instance | Detect, segment, and differentiate individual objects. | Counting and tracking each unique product on a conveyor belt. |
| Panoptic | Provide a complete scene understanding by labeling every pixel with a class and, for countable objects, a unique instance ID. | A delivery drone identifying individual people to avoid while also understanding the general layout of the ground (grass vs. sidewalk). |
Ultimately, the choice between them comes down to one question: what level of detail does your application really need? Answering that will point you directly to the right segmentation strategy.
The Deep Learning Models That Power Modern AI Vision
To really get what makes modern image segmentation tick, you have to look at the deep learning architectures doing the heavy lifting. Think of these models as the brains behind computer vision, turning a chaotic mess of pixels into a structured, understandable map. It's a massive leap from the old days of hand-coded rules to systems that genuinely learn from what they see.
These models didn't just appear overnight. Their story begins with early neural network concepts from the mid-20th century. But things really got interesting in the 1980s with a model called the "Neocognitron," which first introduced the kind of multi-layer convolutional structure we see today. For a long time, the biggest roadblock was a lack of computing power. The explosion in GPU technology and smarter training methods finally unleashed their potential, pushing segmentation accuracy past 95% in demanding fields like autonomous driving.
Fully Convolutional Networks: The First Big Leap
The first true game-changer for segmentation was the Fully Convolutional Network (FCN). Before FCNs, the best neural networks were great at classification—they could tell you a photo had a cat in it, but they had no idea where the cat was.
FCNs brilliantly solved this by swapping out the final layers of a typical classification network with more convolutional layers. Suddenly, the network could take an image of any size and spit out a pixel-by-pixel segmentation map of the exact same dimensions. This was the breakthrough that made practical, end-to-end semantic segmentation a reality.
U-Net: Precision Through Elegant Design
Building on the foundation laid by FCNs, U-Net came along with an elegant and incredibly powerful architecture, originally created to analyze biomedical images. It gets its name from its distinctive U-shape, which is built around two key pathways.
- The Encoder (Downsampling Path): This is the first half of the "U." It works like a standard convolutional network, compressing the image down to capture high-level context—the "what" is in the picture.
- The Decoder (Upsampling Path): The other half of the "U" meticulously rebuilds the image. It upsamples the compressed data, step by step, to restore the precise spatial information—the "where."
The real magic of U-Net, though, is its use of "skip connections." These are direct links that pipe detailed information from the encoder straight over to the corresponding layers in the decoder.
This simple but brilliant trick lets the network merge broad, contextual understanding with fine-grained, low-level details. The result is razor-sharp segmentation, especially around object edges, which is why U-Net is still a go-to model in medical imaging.
DeepLab: Pushing Contextual Understanding
Then came the DeepLab family of models, which introduced another clever trick to help networks see the bigger picture: atrous convolution. Sometimes called dilated convolution, this technique lets the network see a wider area by processing pixels with gaps in between, rather than just the immediate neighbors.
It's like giving the model tunnel vision and a wide-angle lens at the same time, all without bogging down the GPU. This allows the network to capture details at multiple scales—it can see the fine texture of a tire while also recognizing that the tire is part of a car, which is on a road. This kind of multi-scale context is crucial for accurately segmenting busy, real-world scenes.
For startups building solutions on this kind of advanced technology, support from initiatives like the Nvidia Inception program can be invaluable for getting off the ground.
How Image Segmentation Is Changing Industries
It's one thing to understand the algorithms, but the real magic of image segmentation happens when you see it solving tangible, high-stakes problems out in the world. This isn't just an academic exercise; it's a practical tool that has become a cornerstone of progress in critical industries, from saving lives in hospitals to making our roads safer.
By giving machines the ability to see and understand the world with pixel-level precision, segmentation is unlocking capabilities that once felt like science fiction. Think of it as the core sense of sight for artificial intelligence, allowing systems to perceive, interpret, and act on visual information with incredible accuracy and speed.
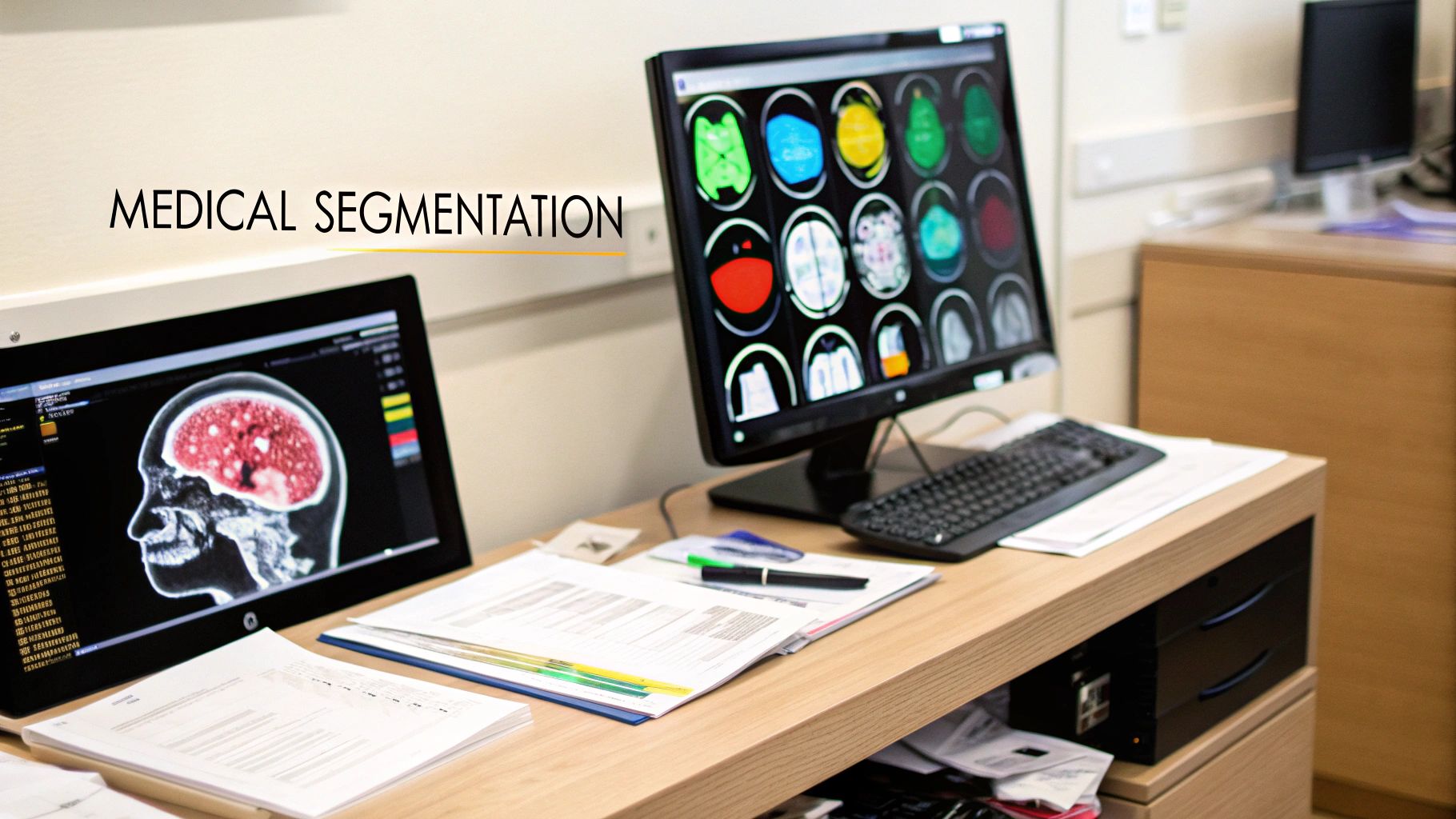
Transforming Healthcare and Medical Diagnostics
Nowhere is the impact of image segmentation more profound than in healthcare. For a radiologist, it’s like having a super-powered assistant that can meticulously outline a tumor in an MRI or CT scan, often with a precision that surpasses the human eye. This leads to more accurate diagnoses, better treatment planning, and a clearer picture of how a disease is progressing. In fact, image segmentation is at the very heart of many innovative applications in healthcare, driving the next wave of diagnostic and surgical tools.
It’s also becoming a key player in the operating room. Surgeons now use segmentation to guide robotic-assisted procedures, relying on real-time visual maps that can clearly distinguish between delicate nerves, blood vessels, and other tissues.
Powering the Future of Autonomous Vehicles
For a self-driving car, image segmentation isn't just a feature—it's the fundamental sense of sight. To navigate safely, an autonomous vehicle has to understand its surroundings instantly and flawlessly. It's not enough for the car to know that a pedestrian is nearby; the system needs to know the exact pixels that make up that person to predict their movement and avoid a collision.
Segmentation models work in milliseconds to tell the difference between the road and the sidewalk, a moving cyclist and a stationary lamppost, or a lane marking and a shadow on the asphalt. This granular understanding of the scene is absolutely essential for the vehicle to make safe, real-time driving decisions in a chaotic urban environment.
The accuracy of these systems has skyrocketed with deep learning. Older methods struggled to hit 75% pixel-wise accuracy, but modern models like U-Net and DeepLab now consistently achieve over 90% accuracy on tough datasets. That's a critical threshold for safety-first applications like autonomous driving.
This leap in performance has been a massive driver for the global autonomous vehicle market, which is on track to blow past USD 20 billion by 2030. This level of precision, fueled by high-quality annotated data, is what makes reliable self-driving technology a reality. The quality of this data often depends on the expertise of the teams creating it, and exploring the top data annotation service companies can provide insight into the industry leaders.
Innovations in Agriculture and Retail
The applications don't stop with medicine and transportation. The versatility of image segmentation makes it a powerful tool in some unexpected places.
- Precision Agriculture: Farmers use segmentation to analyze satellite and drone imagery to monitor crop health. By identifying specific areas affected by pests, disease, or dehydration, they can apply resources exactly where they're needed, which boosts yields and cuts down on waste.
- Automated Retail: This is the tech behind cashier-less checkout systems. Cameras use instance segmentation to identify and track every single item a customer picks up, creating a virtual shopping cart in real-time for a true walk-out shopping experience.
- Geospatial Analysis: Environmental scientists lean on segmentation to analyze satellite photos to track deforestation, monitor the melting of polar ice caps, and classify land use. It’s helping us better understand—and hopefully protect—our planet.
From the farm to the local grocery store, image segmentation is building smarter, more efficient systems that are fundamentally changing how these industries work.
The Critical Role of Data in Building Accurate Models
You can have the most sophisticated algorithm in the world, but it's only as good as the data you feed it. Even powerhouse models like U-Net or DeepLab are destined to fail if they're trained on messy, inconsistent, or just plain wrong information. This gets to the heart of what makes or breaks an image segmentation project: high-quality data.
This essential data is what we call ground truth. Think of it as the pixel-perfect answer key that teaches an AI what to look for and where. Creating this ground truth is a massive undertaking, blending artistry with scientific precision. It takes an incredible amount of effort, specialized knowledge, and strict quality control to make sure every single pixel is labeled correctly.
The Data Annotation Bottleneck
The process of creating ground truth is called data annotation. It’s where human annotators painstakingly trace the outline of every object across thousands upon thousands of images, assigning the right labels. For a self-driving car, this means outlining every car, pedestrian, and traffic sign. For a medical AI, it means precisely mapping the borders of a tumor.
As you can imagine, this work is incredibly slow and demands a very specific skill set. A tiny mistake—even just a few mislabeled pixels along an object’s edge—can teach the model the wrong thing, which leads to poor performance when it matters most. This is the infamous data bottleneck, where innovation grinds to a halt because teams are spending more time labeling data than actually building models.
High-quality data isn't just a "nice-to-have"; it's the bedrock of a reliable AI system. Research consistently shows that the quality and volume of training data have a more significant impact on model performance than minor algorithmic tweaks.
This is exactly where a specialized data partner comes in. Instead of trying to build an expert annotation team from the ground up, companies can work with teams that already have the right tools, proven workflows, and a trained workforce ready to produce perfect datasets at scale.
These partners deliver the clean, accurately labeled data that high-performing segmentation models desperately need. You can learn more about how professional image annotation services help speed up AI development by giving your models the best possible data to learn from.
Ultimately, this lets your development team get back to what they do best: building and improving the next generation of computer vision systems. When your data is solid, your model actually has a chance to be great.
Common Questions About Image Segmentation
As you dive into computer vision, you’ll naturally run into some recurring questions about image segmentation. Getting a handle on these common points helps clarify how this technology works and where it fits into the bigger AI picture. Let's break down a few of the most frequent ones.
How Is Segmentation Different from Object Detection?
This is easily the most common question, and the difference is fundamental. Object detection is all about drawing a simple box around an object. Its job is to tell you two things: that an object is present (like a "car") and roughly where it is.
Image segmentation, however, goes much, much deeper. Instead of a simple bounding box, it carefully traces the exact outline of the object, pixel by pixel. It doesn't just find the object; it understands its precise shape, size, and boundaries.
Think of it like this: object detection puts a frame around a painting on the wall. Image segmentation creates a perfect, detailed stencil of the person in the painting. It’s this pixel-level precision that opens the door to so many advanced applications.
How Much Data Does a Segmentation Model Need?
There's no single magic number, as it always depends on the project's complexity, but deep learning models are famously data-hungry. A professional, production-grade segmentation model will almost always need thousands of high-quality images, each with painstaking, pixel-perfect annotations. This process of creating the "ground truth" data is often the most demanding part of the whole project.
Sure, you can use techniques like data augmentation—creating slightly different versions of your existing images—to stretch your dataset. But there’s really no substitute for starting with a large, diverse, and accurately labeled set of images. The quality of your data is the single biggest factor that will determine how well your model performs in the real world.
What Are the Biggest Challenges in Image Segmentation?
Image segmentation is powerful, but getting it right comes with some significant hurdles. Teams consistently run into the same core challenges:
- Annotation Cost and Time: Manually creating pixel-perfect masks is incredibly time-consuming and expensive. It demands a skilled team and a serious quality control process, which adds up to a major investment.
- Handling Occlusion: Models can get confused when objects are partially hidden or overlapping with one another. Being able to accurately segment a single person in a dense crowd or a car partially blocked by a tree is still a tough problem to solve.
- Computational Resources: Training a modern segmentation model isn't something you can do on a standard laptop. It requires a lot of computing power, usually from high-end GPUs that can be expensive to buy, access, or maintain.
Working through these challenges takes both expertise and the right resources. At Zilo AI, we provide the expert data annotation services needed to build high-performing segmentation models, letting your team focus on the core innovation. Learn more at https://ziloservices.com.